AIPM要知道的NLP知识(1):词的表达
编辑导语:NLP为Neuro-Linguistic Programming的缩写,是研究思维、语言和行为中的纪律;这是一种对优秀(excellence)举办编码和复制的 *** ,它能使你不绝到达你和你的公司想要的功效;本文是作者关于NLP常识中词的表达的分享,我们一起来看一下。

小我私家认为pm懂一点技能长处是大大的有。
总结这个系列,把NLP相关的常见模子举办了梳理,分为词的表达、RNN、seq2seq、transformer和bert五个部门。
根基的想法是重点领略模子是什么(what)、为什么要用这种模子(why)以及哪些场景中可以用这种模子(where),至于如何实现模子(how)可以留给RD小哥哥们。
一、词的表达要知道计较机是看不懂人类语言的,要想让呆板领略语言、实现自然语言处理惩罚,之一步就是把自然语言转化成计较机语言——数字。
由于词是人类语言表达时的一种根基单元(虽然更细的单元是字可能字母),NLP处理惩罚的时候很自然的想要用一组特定的数字代表一个特定的词,这就是词的表达,把这些暗示词的数字连起来就可以表达一句话、一篇文章了。
这一part里有许多常见的名词,distributed representation、word embedding、word2vec等等,它们的干系或许是这样的:

表达 *** ,我以为就是自然语言到呆板语言怎么转化的一套法则;好比“我”这个词转化到呆板语言应该用“1”照旧“100”暗示呢?并且呆板语言中代表“我”的这个数还不能和代表其他词的数反复吧,必需是一个独一的id。
顺着id这个思路,假设我们的辞书收录了10个词,那么我们就给辞书里的每一个词分派一个独一的id;词暗示的时候用一个和字典一样长的向量暗示,这个向量里只有id这一位为1,其他位都为0;好比说abandon这个词的id是1,那么就暗示成abandon=[1 0 0 0 0 0 0 0 0 0],这就是one-hot representation。
这种暗示好领略,可是也有问题:
问题一:向量会跟着字典变大而变大。
很明明假如我的辞书有100000个词的话,每一个词都要用长度100000的向量暗示;假如一句话有20个词,那么就是一个100000*20的矩阵了,按这种操纵根基就走远了。
别的一个问题是这种暗示不能浮现语义的相关性。
好比香蕉和苹果在人看来长短常雷同的,可是用one-hot暗示香蕉大概是[1,0,0,0,0],苹果大概是[0,0,1,0,0],之间没有任何相关性;这样的话假如我们用“我吃了香蕉”练习模子,功效模子大概并不能领略“我吃了苹果”,泛化本领就很差。
于是机警的大佬们提出了一个假说,就是distributed hypothesis:词的语义由其上下文抉择。
基于这种假说生成的暗示就叫做distributed representation,用在词暗示时也就是word embedding,中文名有词向量、词嵌入;所以distributed representation≈word embedding,因为现阶段主流的nlp处理惩罚多半是基于词的,虽然也有对字、句子、甚至文章举办embedding的,所以不能说完全完全相等。
至于详细如何基于这种假说实现词暗示,按照模子差异可以分成基于矩阵(GloVe)、基于聚类、基于神经 *** (NNLM、Word2Vec等)的要领。
2. word embedding小我私家领略,从字面意思上看word embedding就是把一个one-hot这样的稀疏矩阵映射成一个更浓密的矩阵;好比上边栗子中abandon用one-hot(辞书巨细为10)暗示为[1 0 0 0 0 0 0 0 0 0];但word embedding大概用维度为2的向量[0.4 0.5]就可以暗示;办理了前边说的one-hot的维渡过大问题,还增大了信息熵,所以word embedding暗示信息的效率要高于one-hot。
但词向量这个名字没有浮现出它暗示语义的本质,所以之一次看到很容易会不知所云;为了说明word embedding可以浮现语义,这时候就可以搬出著名的queen、king、woman、man的栗子了。
(图来自Andrew Ng deeplearning.ai)

上图是通过练习得出的词向量,man=[-1 0.01 0.03 0.09],woman=[1 0.02 0.02 0.01],king=[-0.95 0.93 0.70 0.02],queen=[0.97 0.95 0.69 0.01]。
矩阵相减man-woman=[-2 -0.01 0.01 0.08],king-queen=[-1.92 -0.02 0.01 0.01],两个差值很是临近,可能说两个向量的夹角很小,可以领略为man和woman之间的干系与king和queen之间很是临近;而apple-orange=[-0.01 -0.01 0.05 -0.02]就和man-woman、king-queen相差很大。
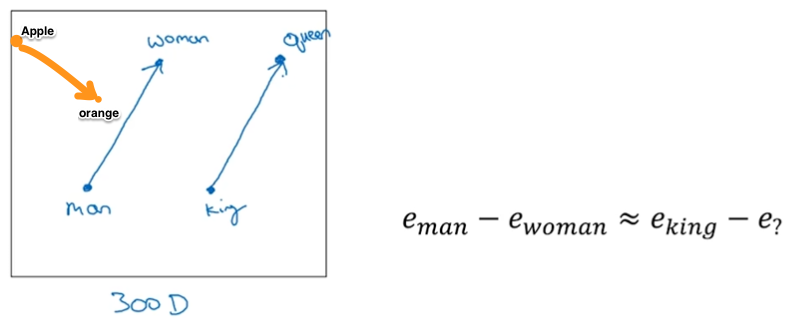
很有意思的是最初word embedding其实是为了练习NNLM(Neural Network Language Model)获得的副产物。
相关文章

原来大厂设计师这么有效率,都是因为这几个窍门!
编辑导语:效率对付任何人来说,都很重要,效率高意味着可以高质量的完成事情,节减时间。大厂的设计师,效率都不会太低。本文作者团结自身的事情履历,为我们总结了一辅佐你晋升效率的要领,但愿看后可以或许对你有...

抖音VS快手,谁吃肉?谁喝汤?
抖音和快手是现今最热门的两个短视频产物,本文通过行业配景、用户数据、产物形态,电商来比拟抖音和快手的成长,到底谁更胜一筹? 一个贸易赛道,有多个产物比拼,但存留下来的却屈指可数。许多人对此不解,为什...

关于直播,看完这篇帮你少走90%的弯路
编辑导语:抖音带货如今固然火热,可是并非所有人都可以带货,这个中有不少的坑和能力。本文作者按照本身的实操履历,对直播举办了阐明总结,但愿可以或许辅佐你少走弯路。 最新动静:抖音声称,从9月6日起,第...

内容营销,要“声量”也要“销量”
编辑导读:2020年的疫情,促使许多企业的业务从线下转酿成了线上。在以短视频为主的内容行业,形成了庞大的用户局限。因此,内容营销的重要性不问可知。本文将从两个方面,环绕内容营销展开阐明,但愿对你有辅佐...

后微信时代,重新看待私域流量
编辑导读:在大平台风浪不绝的本日,把流量把握在本身手里是最保险的做法。私域流量无疑是2020年最火的词之一,每个企业都在摸索私域流量的玩法。本文将从六个方面,探讨在后微信时代,如何做好私域流量,但愿对...

美团借外卖版拼多多偷袭下沉市场?
编辑导读:对付许多都会人来说,外卖已经成为了糊口必备品。可是对付三四线都市及农村来说,外卖照旧一件新鲜事。克日,美团在部门地域测试“拼好饭”产物,意图用拼多多的方法赢得下沉市场。本文从四个方面,环绕该...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!