HTTP被动扫描 *** 的那些事
HTTP *** 这个名词对于安全从业人员应该都是熟知的,我们常用的抓包工具 burp 就是通过配置 HTTP *** 来实现请求的截获修改等。然而国内对这一功能的原理类文章很少,有的甚至有错误。笔者在做 xray 被动 *** 时研究了一下这部分内容,并整理成了这篇文章,这篇文章我们从小白的角度粗略的聊聊 HTTP *** 到底是如何工作的,在实现被动扫描功能时有哪些细节需要注意以及如何科学的处理这些细节。
开始之前我先来一波灵魂6问,读者可以先自行思考下,这些问题将是本文的关键点,并将在文章中一一解答:
1.http_proxy 和 https_proxy 有什么区别?
2.为什么需要信任证书才能扫描 HTTPS 的站点?
3. *** HTTPS 的站点一定需要信任证书吗?
4. *** 的隧道模式下如何区分是不是 TLS 的流量?
5. *** 应如何处理 Websocket 和 HTTP2 的流量?
6.是否应该复用连接以及如何复用连接?
知识储备
我们在本地做开发时,有时会需要启动一个 HTTPS 的服务,通常使用 OpenSSL 自行签发证书并在系统中信任该证书,然后就可以正常使用这个 TLS 服务了。如果没有信任,浏览器就会提示证书不信任而无法访问,简言之,我们需要手动信任自行签发的证书才可以正常访问配置了该证书的网站。那么问题来了,为什么平日访问的那些网站都不需要信任证书呢?打开 baidu.com 查看其证书发现这里其实是一个证书链:

最顶层的 Global Sign RootCA 是一个根证书,第二个是一个中间证书,最后一个才是 baidu 的颁发证书,这三种证书的效力是:
RootCA > Intermediates CA > End-User Cert
而且只要信任了 RootCA 由 RootCA 签发的包括其下级签发的证书都会被信任。而 Global Sign RootCA等是一些默认安装在系统和浏览器中的根证书。这些证书由一些权威机构来维护,可以确保证书的安全和有效性。而内置的这些根证书就允许我们访问一些公共的网站而无需手动信任证书了。
再来说下与 HTTP *** 相关的两个环境变量: HTTP_PROXY 和 HTTPS_PROXY,有的程序使用的是小写的,比如 curl。对于这两个变量,约定俗称的规则如下:
1.如果目标是 HTTP 的,则使用 HTTP_PROXY 中的地址
2.如果目标是 HTTPS 的,则使用 HTTPS_PROXY 中的地址
3.如果对应的环境变量为空,则不使用 ***
这两个环境变量的值是一个 URI,常见的有如下三种形式:
http://127.0.0.1:7777 https://127.0.0.1:7777 socks5://127.0.0.1:7777
抛开与主题无关的 socks 不管,这里又有一个 http 和 https,别晕,这里的 http 和 https 指的是 *** 服务器的类型,类似 http://baidu.com 和 https://baidu.com 一个是裸的 HTTP 服务,一个套了一层 TLS 而已。那么组合一下就有 4 种情况了:
1.http_proxy=http://127.0.0.1:7777
2.https_proxy=http://127.0.0.1:7777
3.http_proxy=https://127.0.0.1:7777
4.https_proxy=https://127.0.0.1:7777
这四种情况都是合法的,也是 *** 实现时应该考虑的。但是如上面所说,这只是约定俗称的,没有哪个 RFC 规定必须这样做,导致上面四种情况在常见的工具中被实现的五花八门,为了避免把大家绕晕,我直接说结论:很多工具对后面两种不支持,比如 wget, python requests, 也就是说 https://还是被当成了 http://,因此我们这里只讨论前两种情况的实现。
*** 中的 MITM
HTTP *** 的协议基于 HTTP,因此 HTTP *** 本身就是一个 HTTP 的服务,而其工作原理本质上就是中间人(MITM) ,即读取当前客户端的 HTTP 请求,从 *** 发送出去并获得响应,然后将响应返回给客户端。其过程类似下面的流程:
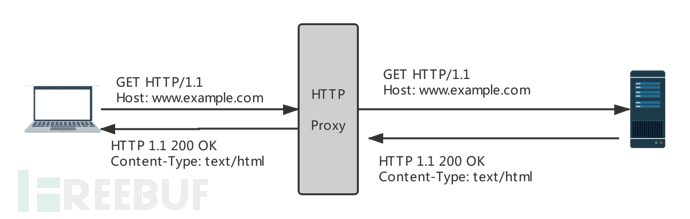
为了更直观的感受下,可以用 nc 监听 127.0.0.1:7777 然后使用
http_proxy=http://127.0.0.1:7777 curl http://example.com
会发现 nc 的数据包为:
GET http://example.com/ HTTP/1.1 Host: example.com Proxy-Connection: keep-alive User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) Accept: text/html Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
看起来和 HTTP 的请求非常像,唯一的区别就是 GET 后的是一个完整的 URI,而不是 path,这主要是方便 *** 得到客户端的原始请求,如果不用完整的 URI,请求的 Scheme 将无从得知,端口号有时也可能是不知道的。
在 Go 中我们可以用几行简单的代码实现这种场景下的 *** 。
package main import ( "bufio" "log" "net" "net/http" ) var client = http.Client{} func main() { listener, err := net.Listen("tcp", "127.0.0.1:7777") if err != nil { log.Fatal(err) } for { conn, err := listener.Accept() if err != nil { log.Fatal(err) } go handleConn(conn) } } func handleConn(conn net.Conn) { // 读取 *** 中的请求 req, err := http.ReadRequest(bufio.NewReader(conn)) if err != nil { log.Println(err) return } req.RequestURI = "" // 发送请求获取响应 resp, err := client.Do(req) if err != nil { log.Println(err) return } // 将响应返还给客户端 _ = resp.Write(conn) _ = conn.Close() }
编译运行这段代码,然后使用 curl 测试下:
http_proxy=http://127.0.0.1:7777 curl -v http://example.com
*** 看起来工作正常,我们使用不到 40 行代码就实现了一个简易的 HTTP *** !代码中的 req 就是做被动 *** 扫描需要用到的请求,把请求复制一份扔给扫描器就可以了。这也就是上面说的之一种情况, 即http_proxy=http://。那么如果直接使用上述实现访问 https 的站点会发生什么呢?
TLS 与隧道 ***
https_proxy=http://127.0.0.1:7777 curl -v https://baidu.com
使用上面的方式访问 baidu 时,出现了比较奇怪的事情——通过 *** 读到的客户端请求不是原来的请求,而是一个 CONNECT 请求:
CONNECT baidu.com:443 HTTP/1.1 Host: baidu.com:443 User-Agent: curl/7.54.0 Proxy-Connection: Keep-Alive
这是 HTTP *** 的另一种形式,称为隧道 *** 。隧道 *** 的过程如下:
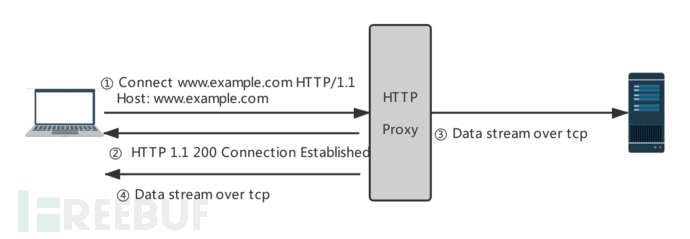
隧道 *** 的出现是为了能在 HTTP 协议基础上传输非 HTTP 的内容。如果你用过 websocket,一定对 Connection: Upgrade 这个头不陌生。这个头是用来告诉 server,客户端想把当前的 HTTP 的连接转为 Websocket 协议通信的连接。类似的,这里的 CONNECT是一种协议转换的请求,但这种转换更像是一种 Degrade,因为握手完成后,这个链接将退化为原始的 Socket Connection,可以在其中传输任意数据。用文字描述下整个过程如下:
1. 客户端想通过 *** 访问https://baidu.com,向 *** 发送 Connect 请求。
2. *** 尝试连接 baidu.com:443,如果连接成功返回一个 200 响应,连接控制权转交个客户端;如果连接失败返回一个 502,连接中止。
3. 客户端收到 200 后,在这个连接中进行 TLS 握手,握手成功后进行正常的 HTTP 传输。
有个点需要注意下,转换后的连接是可以传输任意数据的,并非只是 HTTPS 流量,可以是普通的 HTTP流量,也可以是其他的应用层的协议流量。那么我们回到被动 *** 扫描这个话题,如何获取隧道 *** 中的请求并用来扫描?
这是一个比较棘手的问题,正是由于隧道中的流量可以是任意应用层协议的数据,我们无法确切知道隧道中流量用的哪种协议,所以只能猜一下。查看 TLS 的 RFC 可以发现,TLS 协议开始于一个字节 0×16,这个字节在协议中被称为 ClientHello,那么我们其实就可以根据这之一个字节将协议简单区分为 TLS 流量和非 TLS 流量。对于被动扫描器而言,为了简单起见,我们认为 TLS 的流量就是 HTTPS 流量,非 TLS 流量就是 HTTP 流量。后者和普通 *** 下的 MITM 一致,可以直接复用代码,而 HTTPS 的情况需要多一个 TLS 握手的过程。用伪代码表示就是:
b = conn.Read(1) if b == "0x16" { tlsHandShake(conn) } req = readRequest(conn) handleReq(conn, req)
这里有个细节是读出的这一个字节不要忘记“塞回去”,因为少了一个字节,后面的会操作会失败。
这里我们需要重点关注下 TLS 握手过程。在 TLS 握手过程中会进行证书校验,如果客户端访问的是 baidu.com,server 需要有 baidu.com 这个域的公钥和私钥才能完成握手,可是我们手里哪能有 baidu.com的证书(私钥),那个在文件在 baidu 的服务器上呢!
解决办法就是文章最开始说到的信任根证书。信任根证书后,我们可以在 TLS 握手之前直接签发一个对应域的证书来进行 TLS 握手,这就是包括 burp 在内的所有需要截获 HTTPS 数据包的软件都需要信任一个根证书的原因!有了被系统信任的根证书,我们就可以签出任意的被客户系统信任的具体域的证书,然后就可以剥开 TLS 拿到被动扫描需要的请求了。这里还有一个小问题是签发的证书的域该使用哪个,简单起见我们可以直接使用 CONNECT 过程中的地址,更科学的 *** 我们后面说。签完证书就可以完成 TLS 握手,然后就又和之一节的情况类似了。
有个点需要提一下,如果不需要进行中间人获取客户端请求,是不需要信任证书的,因为这种情况下的是真正的隧道,像是客户端与服务器的直接通信, *** 服务器仅仅在做二进制的数据转发。
至此,被动 *** 的核心实现已经完成了,接下来是一些琐碎的细节,这些细节同样值得注意。
*** 的认证
一个公网的 *** 如果没有加认证是比较危险的,因为 *** 本身就相当于开放了某个 *** 的使用权限,而且由于隧道模式的存在, *** 的支持的协议理论上拓宽到了任何基于 TCP 的协议,如果可以和传统的 redis 未授权,SSRF DNS rebinding 等结合一下就是一个简单的 CTF 题。所以给 *** 加上鉴权是很有必要的。
*** 的认证和正常的 HTTP Basic Auth 很像,只是相关头加了一个 Proxy- 的前缀,可以参考 《HTTP 权威指南》中的一个图学习一下:

点对点的修正
根据 RFC,HTTP 中的下列头被称为单跳头(Hop-By-Hop header),这些 Header 应该只作用于单个 TCP 连接的两端,HTTP *** 在请求中如果遇到了,应当删掉这些头。
"Proxy-Authenticate", "Proxy-Authorization", "Connection", "Keep-Alive", "Proxy-Connection", "Te", "Trailer", "Transfer-Encoding", "Upgrade",
至于这些头要删掉的原因,这里按我的理解简单说下。前两个是和认证相关的,每个 *** 的认证是独立的,所以认证成功应该删掉当前 *** 的认证信息。
中间的三个是用于控制连接状态的,TCP 连接是端到端的,连接状态的维护也应该是针对两端的,即客户端与 *** 服务器, *** 服务器与目的服务器应该是分别维护各自状态的。Proxy-Connection 类似 Connection,是用来指定客户端和 *** 之间的连接是不是 KeepAlive 的, *** 实现时应该兼顾这个要求。对于连接的状态管理,我认为比较科学的方式是分拆而后串联。分拆是说 client->proxy 和 proxy -> server 这两个过程分开处理, client->proxy 的过程每次开启新的 TCP 连接,不做连接复用;而 proxy->server 的过程本质上就是一个普通的 http 请求,所以可以套一个连接池,借助连接池可以复用 TCP 连接。两部分的连接都拨通后,可以将其串联起来,最终效果上就是在遵循 Proxy-Connection 的前提下连接的状态最终与 *** 无关,而是由 client 和 server 共同控制。串联过程在 Go 中可以用两行代码简单搞定:
go io.Copy(conn1, conn2) io.Copy(conn2, conn1)
TE Trailer Transfer-Encoding和请求传输的方式有关。 *** 在读取客户端请求时应该确保正确处理了 chunked 的传输方式后再删除这几个头,由 *** 自行决定在发往目的服务器时要不要使用分块传输。类似的还有 Content-Encoding,这个决定的是请求的压缩方式,也应该在 *** 端被科学的处理掉。好在传输方式这几个头在 Go 的标准库中都有实现,对开发者基本都是透明的,开发者可以直接使用而无需关心具体的逻辑。
Websocket 与 HTTP2
前面提到过 Upgrade,这里再简单说说。这个头常用于从 HTTP 转换到 Websocket 或 HTTP2 协议。对于 Websocket,被动扫描时可以不关注,所以可以直接放行。这里放行的意思是不再去解析,而是类似 Tunnel 那种,单纯的进行数据转发。对于 HTTP2 ,我们可以拒绝这一转换,使得数据协议始终用 HTTP,也算是一个偷懒的捷径。
当然,如果想要做的完善些,就需要套用一下这两种协议的解析,伪装成 Websocket server 或 HTTP2 server,然后做中间人去获取传输数据,有兴趣可以看一下 Python 的 MitmProxy 的实现。
离完美的差距
回顾刚才说的一些要点,这里的被动 *** 实现其实并不完美,主要有这两点:
之一点是隧道模式下,我们强行判定了以 0×16 开头的就是 TLS 流量,协议千千万,这种可能有误判的。其次我们认为 TLS 层下的应用协议一定是 HTTP,这也是不妥的,但对于被动扫描这种场景是足够了。
另一点是隧道模式下证书的签发流程不够完美。如果你用过虚拟主机,或者尝试过在同一地址同一端口上运行多个 HTTP 服务,那一定知道 nginx 中的 server_name 或是 apache 的 VirtualHost。服务器收到 HTTP 请求后会去查看请求的 Host 字段,以此决定使用哪个服务。TLS 模式下有所不同,因为 TLS 握手时服务器没法读取请求,为此 TLS 有个叫 SNI(Server Name Indication)的拓展解决了这个问题,即在 TLS 握手时发送客户端请求的域给服务器,使得在同一 ip 同一端口上运行多个 TLS 服务成为了可能。回到被动 *** 这,之前我们签证书用的域是从 CONNECT 的 HOST 中获取的,其实更好的办法是从 TLS 的握手中读取,这样就需要自行实现 TLS 的握手过程了,具体可以参考下 MitmProxy 的实现。 https://docs.mitmproxy.org/stable/concepts-howmitmproxyworks/
后话
零零散散说了好多,一个看似简单的 HTTP *** 实则暗藏各种玄机。在所有我见过的被动 *** 中,Python 的 MitmProxy 是实现的最全面最科学的,如果你想使用二而不关心其中的细节,推荐大家使用这个库。截止到这篇文章发布,在 Go 中暂时还没有类似 MitmProxy 那般完善的实现,于是我们在写 xray 被动扫描 *** 的时候参考了几个开源的项目并调整了一下,达到了我认为能用的状态。如果我有时间,一定要整一个Go 版的 MitmProxy! (咕咕咕
有一些代码层面的细节没法写到,凡事都要身体力行才能得到一些独到的理解,大家有时间可以亲自尝试下,相信会有不一样的收获。一家之谈,难免有疏漏和谬误,如果发现有问题,可以在评论处指正,或者和我微信交流下: emVtYWw2NjY=。
参考
RFC
How mitmproxy works
https://github.com/google/martian
相关文章

谁是安全行业最 IN 黑客,霸占谷歌热搜15年?
威胁检测管理、事件响应和渗透测试专业公司 Redscan 发布《热搜中的网络安全》报告,基于从2004年到2019年15年间的谷歌趋势(Google Trend) 数据,披露了网络安全历史上的热搜人物...

刷屏朋友圈的“做任务,赚钱App”,到底有啥猫腻?
最近,市场上出现了一些声称可以赚钱的手机App,用户只要根据App的指令完成相应任务就可以获得奖励,吸引了很多消费者的关注。 这些到底是什么任务?怎么赚钱?这类App真能赚到钱吗? 声称阅读、走路...

支付圈拒付乱象:支付公司霸王条款,伪卡产业链猖獗
很多人对拒付这个词可能比较生疏,但是对于混迹支付圈的大大小小的代理商来说,一提起拒付却是如巨石压顶,令人神经格外紧张。因为多数人难以遇到的拒付,可以令这些代理商一夜间倾家荡产。 拒付是拒绝承付的简称...

安全人员在“渗透测试”过程中被逮捕。。。
文章来源:云头条 一家知名网络安全公司的两名安全工作人员与美国衣阿华州(Iowa)签约,在9月份对某些市政大楼(尤其是多幢法院大楼)进行“渗透测试”。他们在工作过程中被捕。尽管衣阿华州承认与县当局沟...

怎么找黑客帮忙盗微信
微信作为聊天软件的巨头行业目标,我们人人都在使用微信,在微信上我们可以文字聊天,语音聊天,发图片发表情都是畅通无阻的,林子大了什么鸟都有,这话一点也不假。 有好人就会有坏人,在老实的人被欺负的太...
微信被盗全过程(黑客盗微信是真的吗)
盗微信号简单吗?怎样简单盗微信号?移动互联网时代即将过去,并迎来一个新时代,即人工智能时代。人工智能已经逐渐占据了传统的移动互联网市场,移动互联网时代最终将成为过去。人工智能时代属于开发者时代,开放可...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!