基于AI的SQL注入检测识别效果专题研究
一、SQL注入原理与检测 ***
SQL注入攻击是web安全防御所面临的最常见攻击手段。攻击者利用web网站没有细致过滤访问者提交的SQL语句的漏洞,构造特殊的输入参数作为访问请求的一部分,通过绕过服务器防护执行恶意SQL命令的方式,获取web服务器系统信息、拷贝或删除文件、操作数据库、甚至提升权限以进行更多恶意行为。
传统的web防护技术采用特征检测的 *** 检测SQL注入,其 *** 是在特定的访问请求URI识别特定的注入参数,根据存在SQL注入漏洞的web服务器类型和版本的不同,编写成千上万的检测规则,且这些规则只能防御已经发现的web服务器上的SQL注入攻击,同时其检测特征也缺乏普适性,难以防御更为复杂的服务器漏洞SQL注入和0day注入攻击。
SQL注入的类型有很多种:
(1)按数据类型,可以分为数字型、字符型和搜索型注入;
(2)按提交方式,可以分为GET型、POST型、Cookie型和HTTP请求头注入;
(3)按执行效果,又可以分为报错注入、盲注、联合查询注入和堆查询注入,这里的盲注又可以细分为bool和基于时间的注入。
为解决以上问题,基于机器学习和深度学习的SQL注入检测技术应运而生,并经检验行之有效。
其典型的技术发展路线如下图所示:


图 SQL注入检测典型算法
1). 机器学习检测 ***
SQL注入的AI检测 *** ,更先出现的是采用特征工程+机器学习 *** 的 *** ,采用统计型等特征提取方式去进行特征工程,之后训练机器学习的各种分类器或集成学习模型,并对真实数据流中是否存在SQL注入攻击进行检测。
统计性特征提取包括词统计的特征提取和专家抽象经验特征提取 *** ,前者一般采用TF-IDF *** 或者N-gram *** ,后者则依赖安全专家的经验。这种 *** 下,数据样本和专家经验是否足够和有效决定了最终检测结果的好坏。
2). 深度学习检测 ***
深度学习模型在自然语言处理领域中也是不断突破,例如将卷积神经 *** CNN用到文本分类中,多个不同尺寸的kernel来提取句子特征信息(类似n-gram的关键信息),更好捕捉文本局部相关性。也可用word2vec及bert/albert预训练语言模型获取上下文关联特征后送入CNN或RNN等模型进行分类,此过程为端到端的学习。
深度学习进行自动特征表征,缺乏结果的可解释性,且需要海量的样本数据。而 *** 安全数据集的稀缺性和不同类别样本的不平衡性制约着深度学习算法的效果。
3). 语义特征提取解决方案
当前,最新的web安全的机器学习 *** ,更关注将机器学习算法与web代码的语义特征相结合的 *** ,不仅关心词汇在样本中的统计特征,也关心词汇的上下文情景语义,取得了比传统检测 *** 和基于统计的AI *** 更佳的实践效果。
为此,本文也是将AI与SQL注入语义特征分析相结合,利用SQL语句语法分析和预训练上下文语义特征,探索用集成学习 *** 检测SQL注入攻击的新 *** 。首先是在HTTP的请求中抽取可疑的SQL命令语句作为模型分析的对象,然后对SQL语句进行词法解析,将SQL文本信息转换成适用只包含SQL 语法结构的词汇序列(例如采用libinjection词法分析),再利用 *** 上基于开源语料词汇预训练的词向量使用SQL注入样本进行再训练获得带有SQL注入语义上下文的词向量,最终利用集成学习 *** 进行SQL注入检测模型的训练,既考虑到数据的语义信息,又一定程度解决了样本不平衡对数据训练测试结果的影响。总体步骤如下图所示:
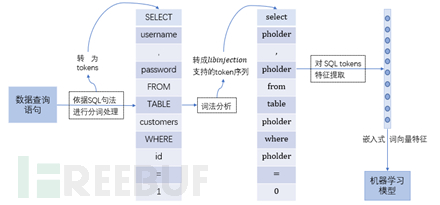
图2 基于语义特征的SQL注入检测模型
二、SQL注入模型技术研究
(一)实验总体流程
本实验是金睛云华基于AI-Matrix建模平台进行实践的, 利用互联网抓取和分析平台获取 *** 上公开的SQL注入攻击样本,利用公司攻击和渗透平台持续积累公司SQL注入相关样本和攻击特征。样本经数据包分析、数据预处理、数据特征提取、AI模型训练步骤得到SQL注入检测模型,然后模型被部署到产品测试环境进行检出效果验证、误报分析和模型重训练。
(二)SQL注入数据收集
获取SQL注入样本的 *** 包括:
收集包含SQL注入和真实查询字符串的开源数据集。例如github上有很多web攻击的数据集包含SQL注入的攻击载荷。
通过扫描工具收集
*** 上专用SQL注入渗透工具例如括SQLMAP、MOLE,以及其他多功能扫描器例如ZAP、Acunetix等,可疑抓取不同使用场景下的SQL注入攻击的攻击载荷。
公司内部研发积累的SQL注入数据
利用公司攻击和渗透开发平台自行收集、开发和验证SQL注入漏洞和相关攻击载荷,也会从实验局和测试环境获取相关数据。黑样本对应AI和特征检测 *** 攻击日志中提取的攻击载荷,白样本是SQL注入检测误报和常见web数据载荷。
(三)数据处理过程
1. 数据预处理
由于对机器学习算法而言,数据的质量对特征提取及训练模型都非常重要。此部分主要是对原始日志数据及开源项目获取文本数据的预处理,如噪声去除、缺失值处理、编码转换和相同数据去重等操作,即如何提取正常数据(白样本)和恶意数据(黑样本)。主要处理过程可如下图所示

图 数据预处理过程
由于训练过程中使用的数据基本都经过了URL编码(有可能多重编码),因此需进行URL循环解码,且为减少数字和其他噪音对样本数据的影响,对如uri、referrer、user agent和cookie等关键字段进行泛化操作,如移除注释、处理链接和将数字替换为0等,最后对文本数据进行分词,可得到模型训练测试所需样本数据。
2. 特征提取
本实验过程中,用于和本 *** 做对比验证的统计型特征使用的是Tf-idf算法,主要是考虑到,该算法较好体现语句中一个词的重要程度,且使用频率和稳定性均较好,可解释性强。而用于和本 *** 做对比验证的语义性特征选取使用具有代表性的word2vec,本 *** 准备采用的更深层次的Bert/Albert预训练语言模型对文本进行特征编码,来提取具有上下文语义信息甚至语法结构的特征表达,丰富表征能力,有利于分类模型进行检测识别SQL注入。
2.1 统计型特征提取
Tf-idf(词频-逆文档词频),其主要思想是,一个词的重要程度与在类别内的词频成正比,与所有类别出现的词数成反比。sql语句中具体计算可如下
考虑到sql语句有长短之分,为便于比较,先进行如下“词频“标准化:

之后,计算逆文档词频,整体的数据样本可视为一个语料库,为避免实际语料中会使分母为0,所以考虑分母加1

这种方式有时候衡量文章中的一个词的重要性是不够全面的,可能重要的词出现次数不够多,而无法体现词相关的位置信息,因此为了研究对比,也实践了下面语义性特征提取的几种 *** 。
2.2 语义性特征提取
(1)Word2vec
将文本通过词向量进行表示,从高维稀疏的神经 *** 难处理的方式,转变为类似图像、语言的连续稠密数据,近而将深度学习算法迁移到文本领域,本实验使用的是默认的CBOW模型,利用上下文预测当前词,且对于文本每个token取得的数字向量按列取更大值(实践效果要比取均值好),每个样本转为(1, n_dim),其中n_dim是特征向量维度。

图 基于CBOW的word2vec
(2)Bert
Bert是利用半监督学习一个双向语言模型,引入词语的位置信息,在进行self-attention时,对输入的sql语句进行上下文信息的编码,且在对数据分词时,如”playing”会分成”play”和”##ing”两个token,以更细粒度的处理去解决未登录词的预测。这里实践代码主要参考苏剑林老师的bert4keras中对文本提取向量的操作,且以句子为单位,对其返回的所有token的特征按列取均值作为最终的句向量。
(3)Albert
Albert主要思想和bert一样,主要是通过对Embedding进行因式分解和跨层参数共享来减少模型参数量,节约模型训练和使用成本,提升效率。
总的来说,语义特征提取过程可如下所示:

图 语义特征提取简要流程
3. 实验数据分析
经过上述的数据预处理之后,我们以下实验所用SQL数据的统计情况,如下表,其中数据文本的平均长度可供语义性特征提取生成向量时的长度截取设置做参考。
SQL样本类型 | 数据量 | 平均文本长度 |
黑样本 | 1214523 | 153 |
白样本 | 2358098 | 120 |
为了更直观了解数据分布情况,下面对数据进行降维描述,以二维平面的数据降维图和三维空间的数据降维图为代表,这里的实验数据均为随机采样后所得,最后由如下分布图可体现数据的可分性较好。


图 数据集t-SNE二维和三维分布图
(四)模型训练及测试
1. 模型选取
由于对SQL注入的检测,主要从特征提取和模型两部分进行操作,选取机器学习 *** 作为分类器,与深度学习bert/albert预训练语言模型等获取的语义特征 *** 相结合,主要考虑如下:
(1)深度学习模型需要大量的数据,而SQLIJ数据样本不易收集,且对于SQL注入精细类别的样本数据很不平衡,对于此特点的数据,不适用深度学习 *** ;
(2)深度学习模型为端到端的过程,模型对数据的处理及预测结果具有不可解释和一定的随机性,且迭代周期较长,不易调参;
(3)经典机器学习 *** ,对于几十万数据的量级可以更好的工作,产品化效率高,可以在较短时间内更快地迭代,且更容易解释,调参和更改模型设计也更简单,即我们可以将特征工程和算法设计分别优化,寻找到更适合于数据特点的模型。
因此,最终选取效率和普适性均较好的LightGBM、RandForest、XGBoost和LogisticRegression算法对SQLIJ数据在不同特征提取下进行模型训练,最后在各分类器下对测试结果进行对比。
此外,在对数据集进行划分时,我们预留20%的数据作为测试集,剩余的数据进行8:2的训练集和验证集划分,用于模型训练和交叉验证选取平均结果。
2. 模型评价性指标
在本次实验中,使用精确率、召回率、准确率以及F1值来综合衡量模型的检测能力。
3.模型对比结果
本实验是在相同SQLIJ数据、不同的特征提取方式下,机器学习选用LightGBM,RandomForest,Xgboost,LogisticRegression算法作为分类器,对各模型的实验从资源消耗、特征处理速度及模型评价指标三方面进行对比,最后综合分析。
对于特征提取方式的选择:词向量提取方式的技术发展路径是word2vec、glove、ELMo到BERT。其中其中BERT是Google2018年发表的模型,在11个经典的NLP任务中测试效果超越之前的更佳模型,并且为下游任务设计了简单至极的接口,改变了以前花销的Attention、Stack等堆叠结构的玩法,应该属于NLP领域里程碑式的贡献。
由于学术界已经论证bert模型超于word2vec等经典模型,所以在本实验中,采用word2vec基于SQL注入样本和bert基于预训练模型根据SQL注入样本微调的 *** 对比,原因是:1) word2vec完全采用SQL注入样本,很可能存在数据过拟合现象作为一种极端样本下和BERT标准模型做对比;2) BERT模型考虑在安全设备上部署注重运行性能,会添加ALBERT(BERT的模型压缩版本)模型对比,均衡考虑检测准确性和运行性能,对word2vec考虑实验时间投入不再添加同条件对比实验项。
(1)词向量模型参数选择
词向量采用不同的模型参数量,对系统资源的消耗和程序运行时间的影响是不一样的,总的来说模型参数量越小,系统资源占用越少且运行越快,但可能牺牲检测准确率。
由于word2vec是根据SQL注入样训练的,而SQL注入样本量总体规模不大(与英文自然语言语料库相比),模型参数量不大。Bert/Albert是基于预训练模型,预训练模型采用英文语料库,不同模型参数量的大小和模型文件总大小对照表如下:
模型参数量 | 预训练模型大小 | |||
Bert | Albert | Bert | Albert | |
base | 108M | 12M | 420MB | 40.5MB |
large | 334M | --- | 1.2GB | --- |
xlarge | 1270M | 59M | --- | 240MB |
xxlarge | --- | 233M | --- | 866MB |
采用模型参数量最小的”base”版本,处理1万条SQL注入样本,使用词向量进行特征提取的时间消耗如下表所示:
Tf-idf | Word2vec | Bert | Albert | |
1万条数据提取特征所需时间(s) | 21 | 53 | 6082 | 1099 |
由上表可知:对相同数据进行特征提取,Bert所需时间是Albert的6倍左右,?是tf-idf提取时间的30倍。分析处理速度差异的原因是:1) bert/albert预训练模型加载需要消耗时间,2) bert/albert预训练的词汇表很大,且计算上下文权重时运算量大,是密集矩阵。而tfidf不带有语义信息,只是简单的词频统计。
因此,考虑实验的验证收敛时间,BERT词向量选择base模型参数进行,而ALBERT(BERT的压缩版本)也在同样条件下使用。
(2)使用Tfidf/Word2vec/Bert/Albert各模型评价指标对比
考虑到不同的词向量提取方式,以下均是,对数据集进行8:2划分为训练集和验证集,使用RF、LR、XGBoost和lightGBM等模型进行训练测试的对比实验结果.
算法指标 | Tf-idf | Word2vec | Bert-base | Albert-base | |
LightGBM 算法 | Accuracy | 0.9883 | 0.9969 | 0.9932 | 0.9370 |
Precision | 0.9685 | 0.9911 | 0.9889 | 0.9218 | |
Recall | 0.9808 | 0.9958 | 0.9816 | 0.7958 | |
F1 | 0.9746 | 0.9934 | 0.9852 | 0.8542 | |
RandForest 算法 | Accuracy | 0.9884 | 0.9972 | 0.9900 | 0.9624 |
Precision | 0.9670 | 0.9927 | 0.9944 | 0.9495 | |
Recall | 0.9828 | 0.9952 | 0.9621 | 0.8850 | |
F1 | 0.9748 | 0.9940 | 0.9780 | 0.9161 | |
Xgboost算法 | Accuracy | 0.9884 | 0.9975 | 0.9963 | 0.9624 |
Precision | 0.9670 | 0.9923 | 0.9929 | 0.9495 | |
Recall | 0.9828 | 0.9968 | 0.9911 | 0.8850 | |
F1 | 0.9748 | 0.9946 | 0.9920 | 0.9161 | |
Logistic Regression 算法 | Accuracy | 0.9700 | 0.9902 | 0.9953 | 0.9319 |
Precision | 0.9570 | 0.9744 | 0.9900 | 0.8790 | |
Recall | 0.9096 | 0.9838 | 0.9900 | 0.8195 | |
F1 | 0.9327 | 0.9791 | 0.9900 | 0.8481 |
由上表的对比可知:
基于词向量的模型word2vec和bert模型表现更佳,比tf-idf这种基于统计特征的特征提取 *** 更好,且基于(自然语言英文语料库)预训练的模型表现与基于SQL注入样本重训练的word2vec模型表现相当。下一步如果基于SQL注入样本微调BERT模型效果会更佳。
ALBERT在同样模型版本(base版本)下,由于模型参数裁剪,表现不佳,说明预训练模型的裁剪还是会损失词汇的语义信息。要想取得好的效果,需要采用更多模型参数的版本,或者于SQL注入样本微调ALBERT模型。
Logistic Regression这种单分类模型和其他对比的集成学习模型相比,不同特征提取 *** 下的准确性和泛化性较集成学习的略低。
以上模型对比,充分证明了提取查询语句中带有上下文语义及位置的信息,可以得到更具有区别性的表征,以提高模型对SQL注入语句的检出效果。
为了更直观的了解各特征下各模型的表现情况,我们举例展示了Tf-idf特征下各模型测试结果的混淆矩阵及ROC曲线图。
Tf-idf特征下各模型测试结果的混淆矩阵及ROC曲线




图 Lightgbm,LogisticRegression,RandomForest,Xgboost测试结果混淆矩阵
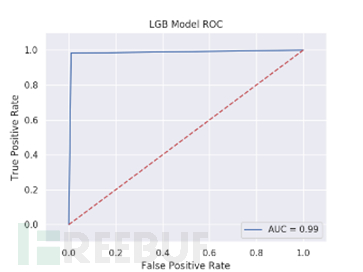
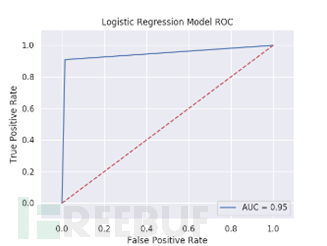
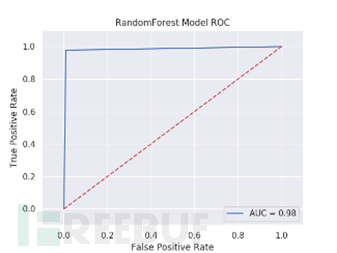

图 Lightgbm,LogisticRegression,RandomForest,Xgboost测试结果ROC曲线
4. 模型迭代与优化
通过对实验数据的比较与分析,可知,各模型对SQL注入的检测能力虽然都很不错,但考虑到注入数据的多变性和语法结构的复杂性,以及模型在真实产品化检测环境下的衡量认证,均需很大成本,因此,可持续调研及迭代优化。
三、总结与展望
在对SQL注入进行检测的实验中我们不难得出,经过对SQL语句提取具有上下文语义信息的特征向量与机器学习分类器相结合的对比实践,可以将数据上下文的语义信息与高效且具有泛化性的机器学习算法进行良好融合,对SQL的注入检测,较经典的统计型特征提取方式进行文本分类要有一定的提升,后续也可以通过网格搜索选取相应模型的更优超参,或者使用集成模型来确定最终的预测结果。
这对以后AI驱动的安全检测具有较强的指导意义,对于具体检测领域的数据特点,我们建议需在实践中持续优化,以找到适用的特征提取和检测模型的最有效融合。
相关文章
美团外卖骑手怎么加入(如何加入美团送外卖)
美团外卖骑手怎么加入(如何加入美团送外卖)就在最近两年外卖行业越来越火爆,我们经常在路上看到小伙子骑着电动车,车上架着一个保温箱,川流在大街小巷,对他们就是我们在网上火爆的称为外面小哥《美团骑手》。那...
苹果手机怎样共享老婆的微信?用什么办法监听老婆的手机和微信!
专业盗取微信密码,开房查询,通话记录查询,查询微信聊天记录,查开房记录,非常靠谱!一个男人在和你微信聊天时,经常不待见你,懒得过问你的事情,在你主动找他话题和他聊时,他却不在意,完全不把你当回事,...

长亭外古道边是什么歌?歌名叫什么,谁唱的
《送别》 作词:李叔同 作曲:John Pond Ordway 演唱:朴树 长亭外 古道边芳草碧连天 晚风拂柳笛声残夕阳山外山 天之涯 地之角知交半零落 一瓢浊酒尽余欢今宵别梦寒 今千...

“闲鱼玩家”用户调研记录——他们是二手市场里的KOL吗
编辑导语:说到“二手生意业务”“出闲置”等等,不少人城市想到闲鱼这个软件,许多用户喜欢用闲鱼的原因不只是因为他可以买到一些想要的和卖出一些闲置的,闲鱼尚有许多生态圈可以留住用户,好比闲鱼的鱼塘,按乐趣...
哪里有查询我家老公删除聊天记录
为加强交通运输行业高技能人才队伍建设,11月12日,由交通运输部、人力资源社会保障部、中华全国总工会和共青团中央主办的第十二届全国交通运输行业“中交兴路杯”道路货运汽车驾驶员职业技能大赛在浙江金华正式...

用什么方法可以白条提现?京东白条如何套到银
京东商城是众所周知的网购平台,也是互联网的巨头之一。京东白条的套现方法比较简单,已经有比较可靠的套现原理和规则,只要能够按照科学的方法进行套现,最终还是可以快速高效的拿到信用额度的钱,用于自己平时的周...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!