Python研究之爬虫练习
本仙女回来啦,阔别已久,分外想念。前天的一次应急响应学到很多内网知识,还认识了很多大厂小哥。对学技术的男孩儿有种天生的好感,比心比心~
呐,今天复习一下爬虫,给你们分享我爬的美女 *** 姐。要是文章有错误,小哥哥 *** 姐请私聊我。
0x00 爬虫前期准备
1. 爬虫就是模拟浏览器抓取东西,爬虫三部曲:数据爬取、数据解析、数据存储
数据爬取:手机端、pc端数据解析:正则表达式数据存储:存储到文件、存储到数据库2. 相关python库
爬虫需要两个库模块:requests和re
1. requests库
requests是比较简单易用的HTTP库,相较于urllib会简洁很多,但由于是第三方库,所以需要安装,文末附上安装教程链接(链接全在后面,这样会比较方便看吧,贴心吧~)
requests库支持的HTTP特性:
保持活动和连接池、Cookie持久性会话、分段文件上传、分块请求等
Requests库中有许多 *** ,所有 *** 在底层的调用都是通过request() *** 实现的,所以严格来说Requests库只有request() *** ,但一般不会直接使用request() *** 。以下介绍Requests库的7个主要的 *** :
①requests.request()
构造一个请求,支撑一下请求的 ***
具体形式:requests.request(method,url,**kwargs)
method:请求方式,对应get,post,put等方式
url:拟获取页面的url连接
**kwargs:控制访问参数
②requests.get()
获取网页HTM网页的主要 *** ,对应HTTP的GET。构造一个向服务器请求资源的Requests对象,返回一个包含服务器资源的Response对象。
Response对象的属性:
| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态(连接成功返回200;连接失败返回404) |
| r.text | HTTP响应内容的字符串形式,即:url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
具体形式:res=requests.get(url)
code=res.text? ? (text为文本形式;bin为二进制;json为json解析)
③requests.head()
获取HTML的网页头部信息,对应HTTP的HEAD
具体形式:res=requests.head(url)
④requests.post()
向网页提交post请求 *** ,对应HTTP的POST
具体形式:res=requests.post(url)
⑤requests.put()
向网页提交put请求 *** ,对应HTTP的PUT
⑥requests.patch()
向网页提交局部修改的请求,对应HTTP的PATCH
⑦requests.delete()
向网页提交删除的请求,对应HTTP的DELETE
2. re正则表达式:(Regular Expression)
一组由字母和符号组成的特殊字符串,作用:从文本中找到你想要的格式的句子
关于 .*? 的解释:
*? ? 匹配前面的子表达式零次或多次。例如,zo能匹配“z”以及“zoo”。等价于{0,}。
? 匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。
.? ? ?匹配除“ ”之外的任何单个字符。要匹配包括“ ”在内的任何字符,请使用像“(.
.*? ?具有贪婪的性质,首先匹配到不能匹配为止,根据后面的正则表达式,会进行回溯。
.*?则相反,一个匹配以后,就往下进行,所以不会进行回溯,具有最小匹配的性质(尽可能匹配少的字符但是要匹配出所有的字符)。
(.*) 是贪婪匹配代表尽可能多的匹配字符因此它将h和l之间所有的字符都匹配了出来
3. xpath解析源码
4. python写爬虫的架构
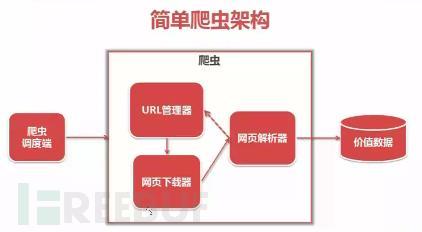
从图上可以看到,整个基础爬虫架构分为5大类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器。
下面给大家依次来介绍一下这5个大类的功能:
① 爬虫调度器:主要是配合调用其他四个模块,所谓调度就是取调用其他的模板。
② URL管理器:就是负责管理URL链接的,URL链接分为已经爬取的和未爬取的,这就需要URL管理器来管理它们,同时它也为获取新URL链接提供接口。
③ HTML下载器:就是将要爬取的页面的HTML下载下来。
④ HTML解析器:就是将要爬取的数据从HTML源码中获取出来,同时也将新的URL链接发送给URL管理器以及将处理后的数据发送给数据存储器。
⑤ 数据存储器:就是将HTML下载器发送过来的数据存储到本地。
0x01 whois爬取
每年,有成百上干万的个人、企业、组织和 *** 机构注册域名,每个注册人都必须提供身份识别信息和联系方式,包括姓名、地址、电子邮件、联系 *** 、管理联系人和技术联系人一这类信息通常被叫做whois数据
0x02 爬取电影信息
0x03 爬取图片
0x04 爬取小仙女
'''头条美女爬取==== *** 一'''import requestsimport re
url='https://www.XX.com/api/search/content/?aid=24&app_name=web_search&offset=0&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis&timestamp=1596180364628&_signature=-Bv0rgAgEBA-TE0juRclmfgatbAAKdC7s6ktYqc7u9jLqXOQ5SBCDkd25scxRvDydd6TgtOw0B7RVuaQxhwY1BwV89sPbdam8LkNuV08d0QfrZqQ4oOOrOukEJ1qxroigLT'
response=requests.get(url)
print(response.status_code)
html_str=response.text
#解析"large_image_url":"(.*?)"
pattern=re.compile('"large_image_url":"(.*?)"')
urls=re.findall(pattern,html_str)
print(urls)def down_load(urls):
for url in urls:
response=requests.get(url)
with open('pic/'+url.split('/')[-1],'wb') as f:
f.write(response.content)
print(url.split('/')[-1],'已经下载成功')
if __name__=='__main__':
down_load(urls)

import re
from urllib.parse import urlencode
#https://www.XX.com/api/search/content/?aid=24&app_name=web_search&offset=0&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20def get_urls(page):
keys={
'aid':'24',
'app_name':'web_search',
'offset':20*page,
'keyword':'美女',
'count':'20'
}
keys_word=urlencode(keys)
url='https://www.XX.com/api/search/content/?'+keys_word
response=requests.get(url)
print(response.status_code)
html_str=response.text
# 解析"large_image_url":"(.*?)"
pattern=re.compile('"large_image_url":"(.*?)"',re.S)
urls=re.findall(pattern, html_str)
return urls#下载图片
def download_imags(urls):
for url in urls:
response=requests.get(url)
with open('pic/'+url.split('/')[-1]+'.jpg','wb') as f:
f.write(response.content)
print(url.split('/')[-1]+'.jpg',"已下载~~")if __name__=='__main__':
for page in range(3):
urls=get_urls(page)
print(urls)
download_imags(urls)

0x05 线程池
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。线程池线程都是后台线程。每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中。
"""线程池"""from concurrent.futures import ThreadPoolExecutorimport time
import threadingdef ban_zhuang(i):
print(threading.current_thread().name,"**开始搬砖{}**".format(i))
time.sleep(2)
print("**员工{}搬砖完成**一共搬砖:{}".format(i,12**2)) ? #将format里的内容输出到{}if __name__=='__main__': ? ? ? ? ? ? #主线程
start_time=time.time()
print(threading.current_thread().name,"开始搬砖")
with ThreadPoolExecutor(max_workers=5) as pool:
for i in range(10):
p=pool.submit(ban_zhuang,i)
end_time=time.time()
print("一共搬砖{}秒".format(end_time-start_time))
结合多线程的爬虫:
'''头条美女爬取'''import requestsimport re
from urllib.parse import urlencode
import timeimport threading
#https://www.XX.com/api/search/content/?aid=24&app_name=web_search&offset=0&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20def get_urls(page):
keys={
'aid':'24',
'app_name':'web_search',
'offset':20*page,
'keyword':'美女',
'count':'20'
}
keys_word=urlencode(keys)
url='https://www.XX.com/api/search/content/?'+keys_word
response=requests.get(url)
print(response.status_code)
html_str=response.text
# 解析"large_image_url":"(.*?)"
pattern=re.compile('"large_image_url":"(.*?)"',re.S)
urls=re.findall(pattern, html_str)
return urls#下载图片
def download_imags(urls):
for url in urls:
try:
response=requests.get(url)
with open('pic/'+url.split('/')[-1]+'.jpg','wb') as f:
f.write(response.content)
print(url.split('/')[-1]+'.jpg',"已下载~~")
except Exception as err:
print('An exception happened: ')
if __name__=='__main__':
start=time.time()
thread=[]
for page in range(3):
urls=get_urls(page)
#print(urls)
#多线程
for url in urls:
th=threading.Thread(target=download_imags,args=(url,))
#download_imags(urls)
thread.append(th)
for t in thread:
t.start()
for t in thread:
t.join()end=time.time()
print('耗时:',end-start)
0X06 tips--爬虫协议
Robots协议,又称作爬虫协议,机器人协议,全名叫做 *** 爬虫排除标准(Robots Exclusion Protocol),是用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取,通常为一个robots.txt文本文件,一般放在网站的根目录下。
Robots协议:在网页的根目录+/robots.txt? 如www.baidu.com/robots.txt
User-agent: Baiduspider Disallow: /baidu Disallow: /s? Disallow: /ulink? Disallow: /link? Disallow: /home/news/data/ Disallow: /bh User-agent: Googlebot Disallow: /baidu Disallow: /s? Disallow: /shifen/ Disallow: /homepage/ Disallow: /cpro Disallow: /ulink? Disallow: /link? Disallow: /home/news/data/ Disallow: /bh
tips:要遵守爬虫协议哟,呐。。只能用于爬着玩儿哈~~~记得挂 *** ~~~(文中的链接我都改过啦,想练手的私聊我,或者自己找链接吧。。。挺好玩儿的啦)
0x07 相关链接
requests的安装与使用? ? https://www.jianshu.com/p/140012f88f8e
re的使用说明? ? https://www.cnblogs.com/vmask/p/6361858.html
其他的爬虫相关文章? ? https://blog.csdn.net/qq_27297393/article/details/81630774
爬虫的视频? ? https://www.imooc.com/learn/563
相关文章
四川屏山:修四好无主之地2发型不好的日子农村路,助力脱贫攻坚
中新网客户端宜宾11月23日电(张旭)近日,交通运输部“行在乡村 游在路上”脱贫攻坚自驾主题宣传活动(四川站)走进宜宾市屏山县。山脚,茂密的砂仁;山腰,连绵起伏的茵红李树;山顶,翠绿的富硒茶园。这...
有没有黑客的联系方式?黑客在线接单网站免费接
对中小站长来说,我们一般只关注以下几点: 1, 速度,节点数量越多,表明加速效果越好。2, 功能,功能当然越多越好。3, 稳定,着重介绍,3天2头访问慢可不好。4, 安全,只要不出问题就好。5, S...
解题神器(逻辑解题神器)
一边放简单搜索、一边放百万或冲顶,开始答题的时候照着答案选就行了 手机解题神器可以下载“师课”APP,最新推出了师课家教宝,里面有很多数学、物理、化学等题目都可以进行搜索答题的。 没有这种东西,学长建...
武当山在哪(国内有7个武当山)
武当山大名鼎鼎,在我国名山大川中占据非常重要的地位,玄天真武大帝、太极张三丰都和它有关。若问起武当山来,估计无人不知,一般都知道武当山在湖北,殊不知在国内武当山并不止湖北一处,在湖北、河北、江西、甘肃...

长安诺启元到底是谁的儿子-长安诺启元的孩子是谁
长安诺是目前正在热播的电视剧之一,茗玉和承煦的感情之路真是让人十分揪心,两人如此相爱却不能在一起,茗玉好不容易答应和承煦一起离开,但边境又突发了战乱,而琪姐姐也不幸离世,临终前将启元和国家交付给了茗玉...
笔记本操作系统(自己如何重装笔记本电脑操作系统呢?)
笔记本操作系统(自己如何重装笔记本电脑操作系统呢?) 笔记本电脑在使用长了以后就免不了会发生一些问题,如卡死、蓝屏、应用崩溃,还有可能感染顽固病毒木马,使用杀毒软件查杀不了,自己又无法解决的时候怎么...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!