“聊骚”屡禁不止,深度学习技术如何对抗语音色情?
在互联网时代,每天各式各样的信息充斥着我们的视野。根据信息的载体不同,我们可以将信息分为文本信息、图片信息、视频信息和音频信息等。内容审核,就是需要对文本、图片、视频和音频等内容进行审核,给各类违禁内容贴上标签并拦截。违禁内容涉及的领域比较宽泛,如色情、暴力、涉政、恐怖等。
人工智能是一项能让机器像人类一样思考和判断的技术。深度学习作为人工智能领域的一个分支,受到了学者和工业界广泛的关注。本文主要介绍基于深度学习的色情语音和?A *** R 语音的识别技术。
一、问题描述
根据业务需求,色情语音和 A *** R 语音属于违禁内容,需要被自动拦截。我们的任务就是通过深度学习模型,从大量客户传入的语音中自动识别色情语音和 A *** R 语音。色情语音指的是男性和女性的 *** 声,而 A *** R 语音指的是自发性知觉经络反应,意思是指“人体通过视、听、触、嗅等感知上的 *** ,在颅内、头皮、背部或身体其他部位产生的令人愉悦的独特 *** 感,又名耳音、颅内 *** 等”(定义来源于百度百科)的语音。
二、系统实现
2.1解决方案与系统架构
我们是用深度卷积神经 *** ,深度循环神经 *** 和注意力机制等模块来构建我们的深度神经 *** ,然后用训练数据训练神经 *** ,等 *** 收敛后,我们固定住 *** 参数,来最终预测输入的语音数据的标签。如下图所示,虚线上方为训练阶段,下方为预测阶段。从图中可知,系统主要包括数据预处理、深度神经 *** 和损失函数设计等几个主要模块。接下来我们分别介绍这几个模块。
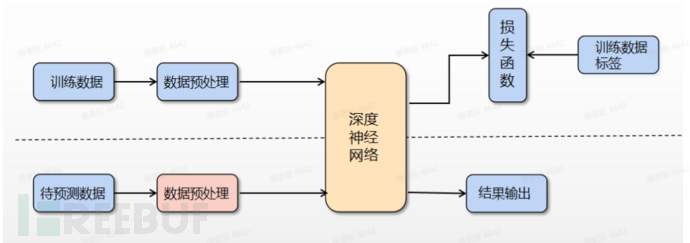
图1 | 解决方案
2.2数据预处理
数据预处理作为音频数据进入神经 *** 的中间步骤,起着承上启下的作用。在训练和预测阶段,数据预处理模块略有不同。训练阶段,预处理主要包括声学特征 FBank 提取和数据增强两个步骤。而预测阶段,该模块仅包含声学特征 FBank 提取这一步骤。声学特征 FBank 特征因为其独特的基于倒谱的提取方式,更加的符合人类的听觉原理,因而在语音任务中,也是最为普遍采用、最有效的声学特征。训练时的数据增强,是希望得到更多的训练数据,使得最终训练收敛后的模型在预测阶段具有更好的鲁棒性。接下来,我们将分别介绍声学特征 FBank 的提取过程和数据增强 *** SpecAugment。
2.2.1 FBank 特征
Fbank 特征的提取大致经过了加窗、傅里叶变换、梅尔滤波等操作,具体流程如下图所示:

图2 | FBank 特征提取过程
之一步为分帧并加窗。其中分帧的主要目的是将语音信号等切分为短时间语音帧,短时间语音帧可以认为是平稳信号,这也是后续傅里叶变换的前提。加窗的主要目的是减小信号的频谱泄漏,一般采用的窗函数为汉明窗或者汉宁窗。加窗与分帧过程如下所示:

图3 | 分帧和加窗(来源:http://www.recognize-speech.com)
第二步为傅里叶变换。傅里叶变换的目的是提取语音的频域信号,经过傅里叶变换之后,我们就得到了每帧语音信号的频谱,将所有频谱按时间顺序排列得到如下的语谱图:

图4 | 语谱图
第三、四步分别为梅尔滤波和取对数操作。梅尔滤波的原因在于研究发现,人耳对声音频率变化的敏感程度是不一致的。在低频区域,声音频率稍加变化,人耳就能察觉出来。但是在高频区域,需要比低频区域变化更大的能量,人耳才能感知到其发生了变化。这一步骤利用一组特定滤波器并接上后续的对数操作来模拟人耳的听觉特性。
2.2.2 数据增强 *** SpecAugment
SpecAugment 是 Google 提出的一种音频数据增强方式。它通过扭曲时域信号,掩盖频域通道与时域通道,修改了频谱图。这种增强方式可以用来增加 *** 的鲁棒性,来对抗时域上的变形,以及频域上的部分片段损失。下面展示了一个增强的例子。
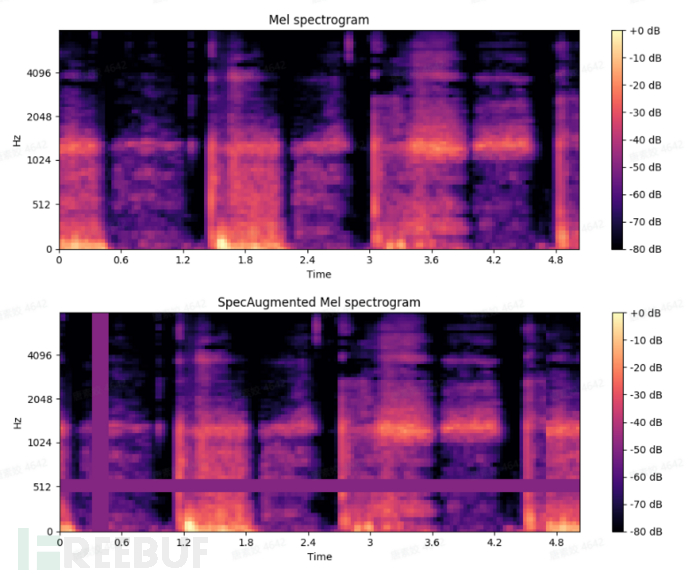
图5 | SpecAugment
2.3 深度神经 *** 模型设计
在介绍完数据预处理模块之后,我们现在介绍图1中的深度神经 *** 模型结构,如下图所示:

图6 | 语音分类模型图
如图6所示,语音数据经过数据预处理之后,得到 FBank 特征 , FBank 特征依次经过卷积神经 *** (CNN) ,循环神经 *** (BI-LSTM) ,注意力模块 (Attention) ,最后经过全连接层和 SoftMax 层输出语音的类别。
之一阶段,使用 CNN *** 来做语音特征的进一步提取。尽管预处理得到的 FBank 特征已经是语音信号很好的特征表达,但是 FBank 通用性很强,在语音各个任务里面都有着广泛的应用,我们为了得到对色情和 A *** R 语音分类更有效的语音特征,我们需要通过 CNN *** 来提取。CNN 主要是做了局部特征的提取,在色情和 A *** R 语音分类任务中,带有显著违禁特征的片段会对结果有比较关键的影响,所以 CNN *** 可以很好地工作在此任务中。
第二阶段,将 CNN 提取到的特征通过 LSTM 来进一步提取语音特征。因为 LSTM 能更有效地捕捉序列的前后依赖和上下文关系。在色情语音和 A *** R 语音识别中,上下文信息对提高分类的准确性会有所帮助,因为一般来讲色情语音出现在背景音较安静的房间内的概率,要比出现在背景音很嘈噪的大街上大很多。
第三阶段,引入 Attention 机制, Attention 可以帮助模型关注到对分类更有帮助的特征。我们发现近年来基于 Attention 的模型已越来越多地被用于谷歌、 Facebook 和 Salesforce 等大型公司的 AI 研究。
最后通过全连接层和 Softmax 层输出最终语音的类别。
三、总结
本文主要介绍了基于深度学习的色情语音和?A *** R 语音的识别技术。首先介绍了数据预处理,以及模型的设计,接着介绍了评测方案,最后给出了结论。相关内容已经整理成专利交由专利局审核,期待利用先进技术高效地对抗语音中的色情内容。
【本文来自于易盾技术团队,作者为板锅锅】
相关文章
专访:中国经济向程茵好有助于世界经济复苏
新华社伊斯兰堡12月20日电 专访:中国经济向好有助于世界经济复苏——访巴基斯坦可持续发展政策研究所中国研究中心主任沙基勒·拉迈 新华社记者刘天 巴基斯坦可持续发展政策研究所中国研究中...

怎么找黑客买装备-黑客x档案免费阅读(黑客x档案电子书下载)
怎么找黑客买装备相关问题 黑客入侵网站相关问题 访问了黑客攻击的网站会怎么样 360在安全领域的地位(360安全浏览器)...

找黑客盗微信要600-黑客技术软件安卓版(黑客技术棋牌透视软件)
找黑客盗微信要600相关问题 网上找的黑客是真的吗相关问题 黑客云现在怎么用 无线摄像头连接手机(无线摄像头用手机接收)...
妻子的微信 我能同时吸收吗
每日好文 妻子的微信 我能同时吸收吗 网络时代给我们的糊口带来了许多惊喜,每小我私家在网上交伴侣都很利便。 此刻,大大都人通过互联网交伴侣,因为互联网上有许多约会软件,许多人事情很忙,业余时间很...
用微信怎定位老公手机(微信偷偷定位不被发现
近日微软推送8月份的更新补丁,通过系统或安全软件进行补丁更新后,可能会导致用户电脑重启后出现开机0xc0000005,0xc0000008e蓝屏,同时无法开机的现象,反复重新启动。此现象与KB285...
不用输入密码 如何登陆老公微信查看他微信聊天记录
不用输入密码 如何登陆老公微信查看他微信聊天记录【黑客徽信:】专业盗取微信密码,开房查询,通话记录查询,查询微信聊天记录,非常靠谱! 微信用户十多亿,庞大的用户组自然会产生很多重复的名字,在浩瀚的人海...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!