针对“小度”体验问题,聊聊语音交互解决方案
近几年来,智能音箱的普及度非常高,不少人都会选择购置智能音箱并通过语音进行简单的交互。然而,也有很多人在使用过程中,发现智能音箱存在着一些“听不懂人话”的缺点……

作为小度音箱(无屏基础版)的用户,本文针对使用中的一个体验细节进行分析,并尝试给出语音交互的解决方案。
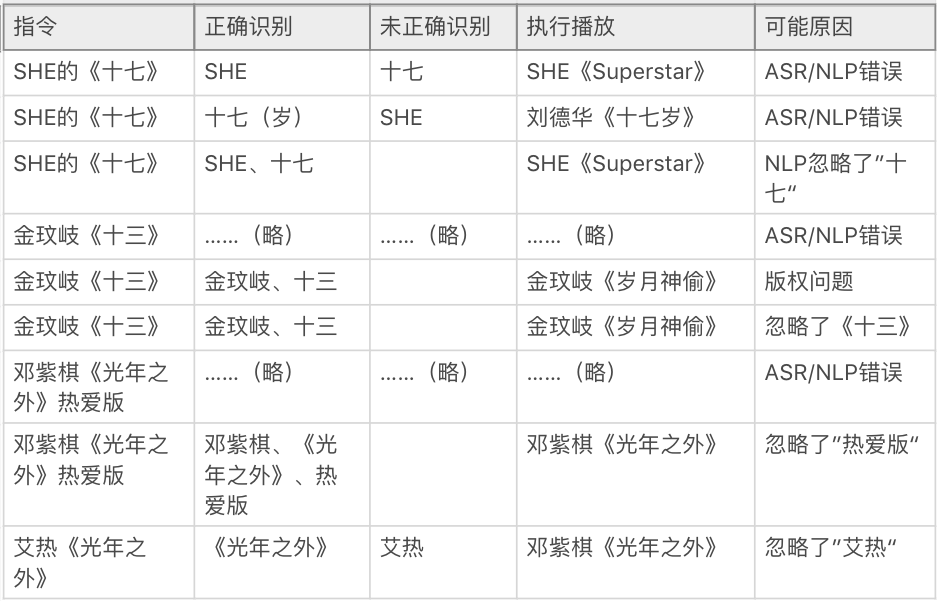
一、CASE示例 场景1用户:小度小度,播放金玟岐的《十三》/播放SHE的《十七》
小度:好的,播放金玟岐的《岁月神偷》/好的,播放SHE的《super star》
用户:小度小度,播放金玟岐的《十三》/播放SHE的《十七》
小度:好的,播放金玟岐的《岁月神偷》/好的,播放刘德华的《十七岁》
……
无限循环
场景2用户:小度小度,播放邓紫棋、艾热的《光年之外》/播放邓紫棋的《光年之外》热爱版
小度:好的,播放邓紫棋的的《光年之外》
用户:小度小度,播放艾热的《光年之外》/播放邓紫棋的《光年之外》热爱版
小度:好的,播放邓紫棋的的《光年之外》
……
无限循环
二、问题抽象问题1:当播放音乐的语音指令有2到3个甚至多个约束条件的时候,DuerOS有时会回应错误
问题2:即使用户”字正腔圆、咬牙切齿“的反复重复同一条指令,DuerOS仍会在多个错误回应之间循环切换,反复给出错误的回应
三、问题可能原因分析 1. ASR(自动语音识别)识别错误或NLU(自然语言处理)分词、忽略关键条件等错误也就是说,在系统看来,它所收到的指令,前者可能类似于”播放SHE的’时期‘“,后者则类似于”播放SHE的十/七“或者“播放SHE”(忽略了“《十七》”之类,理解的错误造成了小度无法正确播放。
2. 版权问题经验证小度的音乐版权服务方,百度音乐和 *** 音乐都没有金玟岐的《十三》的版权,但有其他几首歌的版权,因此版权理应也不是这个体验洼地的主要原因。
相比问题1,问题2才是造成这个体验洼地的关键。这是因为,在小度已经无法正确识别用户意图的同时,没有通过进入对话模式给用户提供更多解决问题的方案,而是机械的重复系统里置信度更高的操作,这无疑会使得用户火冒三丈。
所谓“对话模式”通常有多轮的语音交互,并且AI能够理解用户的上下文含义,从而更“聪明”地做出回应,举个经典的例子:
用户:谁是美国的第16任总统
AI:林肯
用户:他去世时多大?
AI:林肯享年65岁
对话模式中,AI承接了上文的“他”指的是“林肯”;而如果是非对话模式,AI则会对用户的第二句“他”不知所措。
目前的策略,一般情况下小度与用户之间的交互是单轮命令式的,即用户“小度小度”唤醒后给予小度指令,小度会做出单次回应。
但有以下两种情况(记忆中观察到的,因为疫情影响手边没有产品,应该会有情况遗漏)小度会切换到对话模式:
当用户主动说出“进入极客模式”或者“来聊聊天吧”之类的指令
当小度“不自信”的时候。比如给予的指令小度理解不清楚、小度为了消除指令的歧义、或者出现打断对话等异常情况时,小度会采用各种确认策略,反复确认用户的指令,这样也就进入了多轮对话
所以在现有常规的交互策略下,当小度“自信”的时候,比如他自信地忽略掉了一些限定词(例如艾热、热爱版),从而自信地认为用户就是想听邓紫棋原版的《光年之外》,这时它一般不会进入对话模式。
尽管用户火冒三丈地多次重复同样的“播放《光年之外》艾热版”的指令,小度依然会我行我素地播放邓紫棋原版的《光年之外》。
我不清楚这种策略设置的决策依据是什么,可能是这种case比较极端没有被注意到,可能是技术限制,也可能是出于成本考虑,在此不做判断,但不影响从体验优化的角度给出建议。
四、尝试给出解决方案 问题1的解决结论:出于可能的成本考虑,“版权问题”的情况自动进入对话模式,其他由于AI能力问题造成的错误,交由问题2的解决方案一并解决。
示例对话:
用户:小度小度,播放金玟岐的《十三》
小度:对不起,暂时没有相关歌曲的播放版权,是否为您播放金玟岐的《岁月神偷》
用户:好的
GUI原型:无
VUI交互流程:

结论:当用户反复唤醒小度重复相同指令时(先为“播放下一曲”之类的命令加白,不在此讨论之列),自动进入对话模式。
功能逻辑:

这里有几个概念需要解释:
1)确认策略
相关文章

“漏洞百出”的智能音箱:潜力十足但仍需打磨
编辑导读:固然当前的智能音箱存在着诸多问题,但在当前智能家居观念的一连火热之下,智能音箱市场的将来仍极具潜力。本文作者全面细致地阐明白智能音箱存在的诸多裂痕和其将来成长偏向,辅佐各人更深入地相识智能音...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!