基于AI的暗网流量检测识别效果专题研究
1、暗网背景介绍
暗网是深网中的一小部分,是必须通过特殊的软件、特殊的配置才能访问的拥有特殊域名的Web站点,搜索引擎无法对其进行直接检索。它的网址不同于一般的网址,它以顶级域名后缀“.onion”结尾,且一般的浏览器无法对其进行访问,只有通过暗网的浏览器才能进行访问,比如Tor浏览器。Tor是一个自由软件,它专注于提供对互联网的匿名访问,可以让用户匿名上网。由于Tor *** 经过了多层次的加密,网站无法跟踪其用户的地理位置和IP,用户也无法获取网站主机的有关信息。因此,黑暗 *** 用户之间的通信是高度加密的,用户可以以保密的方式交流、共享文件、发布博客等,同时也会被用于非法交易、非法论坛等的介质交流等。
访问Tor *** 的时候,需要在客户端上安装一个Tor浏览器,然后浏览器连接到Tor输入节点,该节点又连接到Tor中继节点。连接将通过多个中继节点,每一步都增加了另一层安全性并重新加密了数据,最终到达要访问的目标网站。如图1所示:
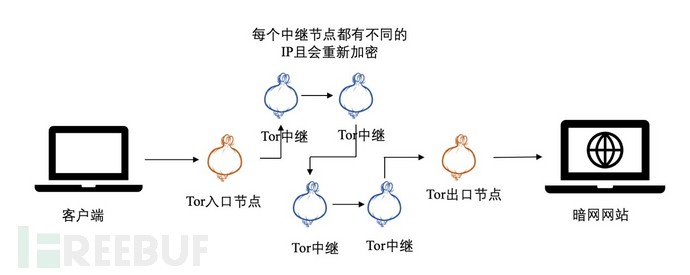
图1 Tor *** 访问拓扑图
为了进一步提高访问的私密性,可以在浏览器中配置 *** 访问Tor入口节点,常见的 *** 方式包括Shadowsocks翻墙 *** 和VPN *** 。
2、暗网内部模拟环境搭建
2.1 拓扑图
本实验为尽可能模拟真实的暗网访问,并在不同的 *** 访问之间抓取Tor流量数据,搭建了完整的暗网访问环境,包括:
1. 自建的访问Tor访问终端;
2. 自建的内网入口节点或者选定的外网入口节点;
3. 外网出口节点
4. 自建的内网目的服务器或者外网的目的服务器。
其中,自建的访问终端搭建了3种不同的访问方式:
1. 直连接入暗网入口节点;
2. 使用Shadowsocks翻墙 *** 接入外网入口节点;
3. 使用VPN *** 接入外网入口节点;
总体的 *** 拓扑如图2所示(红框的是自建的节点):

图2:自建的暗网访问环境拓扑
基于以上拓扑,可以抓取如下类型的流量:
1. Tor终端直连到外网入口节点的流量;2. Tor终端直连到内网入口节点的流量;3. Shadowsocks到外网入口节点流量;4. Tor翻墙 *** 到外网中继节点的流量;5. Tor VPN *** 到外网入口节点的流量;6. 外网出口节点到内网暗网目标服务器的流量即通过在自建的 *** 拓扑中建立自己的节点,能够抓取到暗网通信各个环节中的流量数据。
参照 *** 上公开的Tor研究数据
(https://www.unb.ca/cic/datasets/tor.html),我们抓取的Tor流量也包括如下7类的数据:浏览器上网、电子邮件、聊天、音频流、视频流、FTP、VoIP以及P2P等。
2.2 三种Tor连接方式的典型流量
1. Tor终端直连到内网入口节点的流量

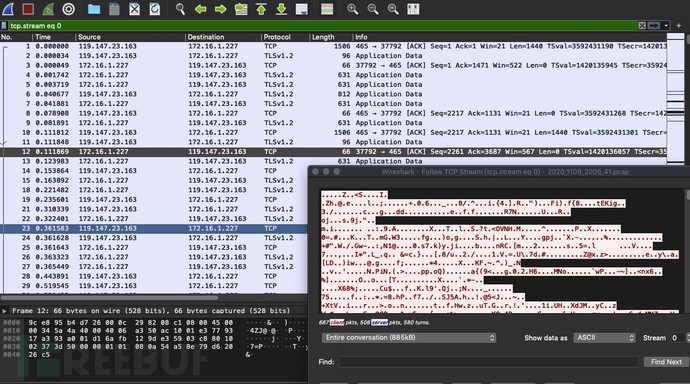
2. Tor Shadowsocks典型流量
3. Tor VPN典型流量
Tor VPN可以配置TCP或者UDP两种 *** 模式,其中Tor VPN TCP典型流量:
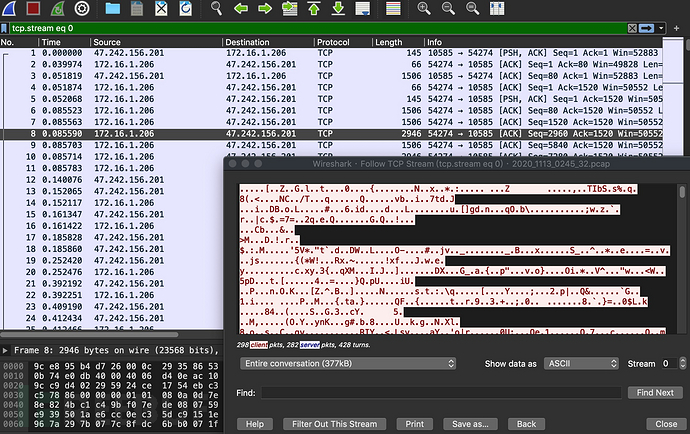
Tor VPN UDP典型流量:

3、实验数据
3.1 实验总体流程
暗网的实验是在公司自建的AI训练平台上进行的,AI训练平台的整体流程图如下图3所示:
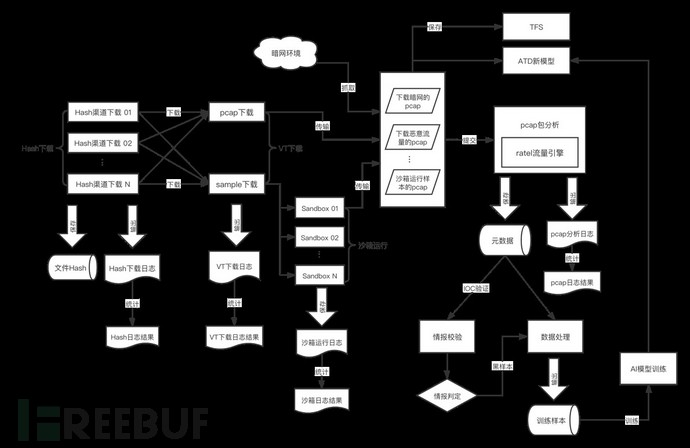
图3 AI训练平台流程图
本次暗网实验,是从暗网环境抓取pcap数据开始,经过下载暗网的pcap、pcap包分析、流量数据处理、流量特征提取、AI模型训练几个步骤,生成暗网的AI模型。
3.2 实验数据
通过搭建暗网环境,抓取到的实验数据集详细分类信息如下:
表1 实验采集数据集
流量类型 | 流量总量(单位: MB) |
Tor_pcaps(Tor直连流量) | 17075 |
Tor_Shadowsocks_pcaps(Shadowsocks *** 流量) | 16220 |
VPN_pcaps(VPN *** 流量) | 4484 |
Benign_pcaps(非Tor流量) | 10114 |
对于加密流量的机器学习检测,通常有两种特征提取方式:
1. 基于数据流上包的统计特征构建AI训练的特征工程;2. 基于加密应用协议TLS/SSL和数据流上包的统计特征,并关联DNS上下文统计特征构建AI训练的特征工程。
本文的实验分别基于以上两种特征提取方式进行AI模型的验证。
4、基于数据流上包统计特征构建模型
4.1 模型评价指标

4.2 模型训练
基于数据流上包的统计特征,提取特征向量之后得到的训练样本如表2所示:

在数据集的模型训练中,选择目前流行度较高的XGBoost、LightGBM、RandForest以及Logistic Regression分类算法进行模型训练,且全部采用算法模型的默认参数进行训练。在数据集的划分中,训练集:测试集:验证集按照4:2:2的比例进行划分,并在训练过程中采用10折交叉验证进行模型训练和结果评估。
基于数据流上包的统计特征对各模型进行训练后,在测试集上得出的评价指标如表3所示:
表3 ?不同算法模型在测试集上的评价结果1
分类模型 | Accuracy | Recall | Precision | F1-score |
XGBoost | 0.99983076 | 0.99582853 | 0.99963828 | 0.99771797 |
LightGBM | 0.99981829 | 0.99350040 | 0.99835846 | 0.99590395 |
Random Forest | 0.99979157 | 0.99414401 | 0.99969957 | 0.99688789 |
Logistic Regression | 0.98330245 | 0.87101271 | 0.95909096 | 0.90579628 |
从结果中可以看到,XGBoost、LightGBM以及Random Forest的各个功能评价指标都达到理想的效果,而LogisticRegression相对较差,其中Recall仅0.87,表明该模型对Tor流量的检出能力不如另外三个模型。
为进一步对模型进行更加准确的评价,将各个模型的ROC曲线图以及混淆矩阵图进行展示,如图5和图6所示,class 0: 白样本,class 1:Tor直连样本,class 2:Shadowsocks *** 样本,class 3: VPN *** 样本。
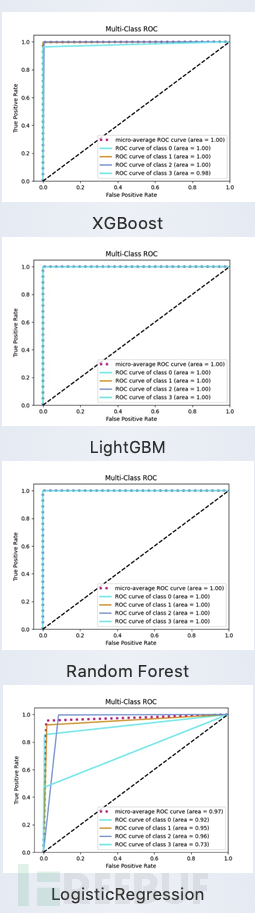

图6 模型 ROC混淆矩阵图
从表3指标评价结果表、ROC曲线以及混淆矩阵图综合来看,XGBoost、LightGBm以及Random Forest在Tor流量的综合检出能力以及各个类别的检出能力上都表现较好,而Logistic Regression则更容易产生误报。
4.3 模型在公开数据集上的验证
模型训练的数据都是在实验环境抓取的,除了对实验数据进行交叉验证之外,我们也利用CIC Tor2016公开数据集
(https://www.unb.ca/cic/datasets/tor.html)验证了模型的检测效果。
该数据集包含22GB的Tor以及nonTor流量,其中Tor流量12GB,nonTor流量9.9GB,Tor流量包含7类:浏览器、电子邮件、聊天、音频流、视频流、FTP、VoIP以及P2P。4.2中所训练的模型在CIC Tor 2016中的TCP/UDP表现如表5所示:
表4 模型在CIC Tor 2016数据集测试结果
模型 | 数据集总量(单位:个) | 准确率(%) | 误报率(%) |
XGBoost | 31494 | 99.9841 | 0.0159 |
LightGBM | 31494 | 99.9841 | 0.0159 |
Random Forest | 31494 | 99.9809 | 0.0191 |
Logistic Regression | 31494 | 85.2766 | 14.7234 |
从表中可以看到,XGBoost、LightGBM误报率都较低,为0.0159%,而Logistic Regression误报达到了14.7234%。
其中,XGBoost、LightGBM将nonTor预测为Tor直连数量为3,将Tor直连预测为nonTor数量为2;Random Forest将nonTor预测为Tor直连数量为4,将Tor直连预测为nonTor数量为2;Logistic Regression将nonTor预测为Tor直连数量为4556,将Tor预测为nonTor数量为80。另外除了Logistic Regression出现了一次将nonTor预测为Tor非直连的情况,其它三种模型均无被预测为Tor非直连的情况。
5、基于加密协议TLS/SSL协议构建模型
基于加密应用协议TLS/SSL进行特征提取,不仅利用了数据流上包的统计特征,而且利用了加密协议TLS/SSL通信特征,并关联DNS上下文统计特征,构建AI训练的特征工程。
5.1 模型训练
表5 基于TLS/SSL并关联DNS上下文统计特征构建的样本
样本类别 | 样本数量 |
白样本 | 194952 |
Tor | 12035 |
shadowsockets | 8021 |
以上数据的降维分布,如图7所示:

图7 样本t-SNE数据分布图
在该数据集的模型训练中,选择目前流行度较高的XGBoost、LightGBM、RandForest以及Logistic Regression分类算法进行模型训练,且全部采用算法模型的默认参数进行训练。在数据集的划分中,训练集:测试集:验证集按照4:2:2的比例进行划分,并在训练过程中采用10折交叉验证进行模型训练和结果评估。模型评价指标采用4.1节中描述的四种功能评价指标。
对各模型进行训练后,在测试集上得出的评价指标如表6所示:
表6 不同算法模型在测试集上的评价结果2
分类模型 | Accuracy | Recall | Precision | F1-score |
XGBoost | 0.99997861 | 0.99977728 | 0.99999229 | 0.99988475 |
LightGBM | 0.99997861 | 0.99977728 | 0.99999230 | 0.99988474 |
Random Forest | 0.99993346 | 0.99935500 | 0.99997604 | 0.99966532 |
Logistic Regression | 0.99973386 | 0.99792784 | 0.99954118 | 0.99873235 |
从结果中可以看到,各个模型在各个功能评价指标上表现都较好。为进一步对模型进行更加准确的评价,将各个模型的ROC曲线图以及混淆矩图进行展示,如图7和图8所示。class 0: 白样本,class 1:Tor直连,class 2:Shadowsocks。


图9 四种模型混淆矩阵图
从表6模型评价指标结果以及图8的ROC曲线以及图9的混淆矩阵图中可以看到,各模型在数据集上的表现都较为稳定,且检测能力较好。
5.2 模型在公开数据集上的验证
模型训练的数据都是在实验环境抓取的,除了对实验数据进行交叉验证之外,同样利用CIC Tor2016公开数据集(https://www.unb.ca/cic/datasets/tor.html)验证了模型的检测效果。
该数据集包含22GB的Tor以及nonTor流量,其中Tor流量12GB,nonTor流量9.9GB,Tor流量包含7类:浏览器、电子邮件、聊天、音频流、视频流、FTP、VoIP以及P2P。
5.1节所训练的模型在CIC Tor 2016中的测试结果如表7所示。
根据表7中的结果,训练模型在CIC Tor 2016数据集的测试中,LightGBM误报率更低,Logistic Regression的误报率则在0.481 %。
表7 模型在CIC Tor 2016中的误报率
模型 | 数据总数(单位:个) | 准确率(%) | 误报率(%) |
XGBoost | 2700 | 99.963 | 0.037 |
LightGBM | 2700 | 100.0 | 0.0 |
Random Forest | 2700 | 99.926 | 0.074 |
Logistic Regression | 2700 | 99.519 | 0.481 |
其中,XGBoost将nonTor预测为Tor直连数量为0,将Tor直连预测为nonTor数量为1;LightGBM无预测出错的情况;Random Forest将nonTor预测为Tor直连数量为0,将Tor直连预测为nonTor数量为2;Logistic Regression将nonTor预测为Tor直连数量为1,将Tor预测为nonTor数量为12。另外训练的四种模型都没有出现被预测为Tor非直连的情况。
6、总结
我们按照暗网的常见 *** 拓扑,搭建的实验环境,利用公司自建的AI训练平台,验证了基于数据流包统计特征和基于加密协议TLS/SSL结合数据流包统计特征、关联DNS上下文统计特征的2种AI模型。
这2种模型都分析了数据集的t-SNE降维分布、模型在不同机器学习算法上的交叉验证结果、在公开数据集上的测试结果,最终结果表明用AI *** 来识别暗网流量是可行的,在有些机器学习算法上表现优异,准确率高达99.8%以上。而且使用AI多分类模型,能够区分暗网的3种连接方式:直连、Shadowsocks *** 和VPN *** 。
相关文章

换了新手机微信记录是否可以恢复「暧昧聊天记录被老公发现」
原标题:换了新手机,怎么恢复微信聊天记录? 今天我们邀请到了果师兄数据恢复团队的工程师,为我们针对数据恢复过程中常见的案例进行分析讲解,告诉我们什么样的情况下微信聊天记录是可以恢复的,如何保...
网站检测提示的“Flash装备不妥”是什么缝隙?
360站长渠道中有一个东西是“官网直达”,经过恳求能够使你的网站在360搜索成果中加上“官网”字样的标识,百度也有这样的东西,不过是收费的,所以趁着360还没收费,有爱好的朋友可认为自己的网站恳求一...
Codiad在线IDE结构缝隙发掘
简介 : Codiad 是一个开源根据Web的IDE应用程序,用于在线编写和修改代码。 库房 : https://github.com/Codiad/Codiad 环境建立 : 经过phpstudy建...
网站开发工具有哪些!
有的人使用记事本写代码、有的人用Dreamweaver写代码,由于每个人的喜好不一样,所以使用的网站开发工具也不一样,今天我来给大家分享几个网站开发的工具和网站开发环境! 1、Dreamweaver...
黑客酒店锁,网络黑客侵袭事件,黑客盗取别人qq密码视频
/Application/Home/Controller/ChartController.class.php:试想一下,一旦这个分组是刚好分为四组,咱们只是将abc与efg交流,那不就形成了付出收款回...
去哪里找电脑黑客,反共黑客网站
一、去哪里电脑怎么找黑客 1、攻击的视频黑客网站不幸的是,许多记者和作家倾向于错误地利用黑客作为黑客来激怒真正的黑客。去哪里电脑反共现在,国王名单上的荣誉是相当高的。基本上,他们去他们的平台接收订单。...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!