基于机器学习的Web管理后台识别 *** 探索
背景
长期以来,Web管理后台一直是攻击者觊觎的目标。部分信息安全意识薄弱的业务在未作任何安全加固(设置IP白名单、强口令、二次认证、验证码、请求频率审计等)的情况下直接将Web管理后台暴露到互联网,而管理后台由于本身的管理和敏感属性,外部一旦攻击成功,则极大可能造成数据泄露和服务器被入侵。
所以,Web管理后台的检测一直是Web漏洞扫描器规则中比较重要的组成部分,而传统识别 *** 基于关键字,误报和漏报的问题比较突出,规则一旦形成,除非人为更改,否则长期处于停滞状态,灵活性较差。此外目前大量网站基于动态网页进行展示,传统扫描器如果不进行 *** 渲染,则漏报严重;而逐个渲染,则时间花销大、成本又非常高。
于是我们将目光转向利用机器学习来识别Web管理后台。此外,笔者所在的团队是基于流量来进行安全分析建设工作的,所以如何利用流量的优势实现对Web管理后台的识别,也是本文一大重点。
传统 VS AI
在介绍具体机器学习的时候我们可以先思考一个非常简单的问题,怎么识别phpinfo页面呢?
答案很简单,我们通常会找一些页面特征作为规则去匹配响应。但是如果针对下图中的页面怎么判定是否为风险呢?
 图片源自spring actuator
图片源自spring actuator
我们当然也可以选择其中一些字段作为关键字去匹配。但是随着业务拥抱开源,这些页面层出不穷,与此同时,他们的规则也不尽相同,如果每次都需要人工制定规则,其消耗无疑是巨大的。同理,Web管理后台的种类也纷繁复杂,这也就是我们为什么要利用机器学习来识别Web管理后台和高危页面的原因。
机器学习方案由于不依赖关键字,具有良好的泛化能力,能识别传统基于关键字方案漏报的部分;同时,模型可通过不断迭代自进化,灵活度高;在识别能力上,机器学习模型是通过综合学习多维特征,建立各维度关联关系,从而指导决策,具备更缜密的判断逻辑。新的识别方案上线之后,也确实有很多意外收获,比如识别出了Django的调试页面等等。
 图1 传统方案与AI方案对比
图1 传统方案与AI方案对比
系统架构
系统在架构上整体分为五大模块,分别是流量识别与落地,URL扫描、机器学习识别以及告警和后台存储调度,五者的关系简单描述如下:
 图2 系统架构
图2 系统架构
一、识别与落地
该模块从公司流量平台获取到的流量作为输入,之后经过两个步骤的处理,之一步是直接利用流量中的响应内容来判定是否为Web管理后台,如果是Web管理后台的话则直接存储;如果判定为非Web管理后台,则进入步骤二。在步骤二中,为了防止漏报,我们需要落地疑似管理后台url用于后续扫描之后再进行判定,这里我们通过四种特征规则来确定:
1. 据登陆行为
提交登录请求中,大多数的请求都比较有类似的特征,这里以GET登录请求,我们限定其中一种登录行为模式为(以正则为例):
URL匹配\wpass\w=\w+和\wuser\w=\w+到该类模式则认为是目标URL,其他模式不再赘述。
2.根据cookie
登录前后的cookie值不同,可以根据header头中的set_cookie字段。
3. 根据关键字
常见的URL有比较明显的特征,比如admin、login、sign等
4. 根据状态码
登录之后的跳转具有302跳转特征码等。
通过上述几个规则落下来的流量,提取出URL加入待扫描列表,包括path和host拼接的URL和referer字段提取的URL,值得一提的是,为了防止漏报我们也对路径做了分割,拆分成多个子目录加入待扫描列表,比如针对http://qq.com/admin/html/index.php,我们会做如下拆分:
经过我们的测试,通过以上四种方式基本可以落地98%以上的登录URL。
二、URL扫描
这里主要是接收识别与落地模块的URL进行扫描。扫描这里自动化方案比较多,比如常见的Selenium、Chrome等等,我们采用的是pyppeteer+Chrome的方案。
这块比较简单,不再赘述,但是也有一些小tips可以跟大家分享,比如扫描速度优化,因为pyppeteer这个库是原生支持asyncio的,所以我们这里采用了多进程+异步的模式来加快扫描速度。
此外,pyppeteer有个BUG,如果利用newPage函数来创建一组协程,当其中一个协程超时时,则整个任务组都会超时,解决这个问题也很简单,可以先用createIncogniteBrowserContext函数创建一个context,之后再利用newPage函数就可以避免这个问题。为了方便读者,这里给下一些具体代码:
另外一个比较坑的地方是pypeteer的close *** 有时候并不能很好的关闭浏览器,我们初期线上跑的时候经常出现内存不足的问题,最后发现基本都是chrome进程过多导致的,所以需要代码加下手动发送signal信号来关闭浏览器,这部分代码也放到下边:
def kill_chrome(self, sig=signal.SIGKILL):
parent_pid=os.getpid()
try:
parent=psutil.Process(parent_pid)
except Exception as e:
return 0
children=parent.children(recursive=True)
for process in children:
try:
process.send_signal(signal.SIGTERM)
except Exception as e:
pass三、机器学习识别
如图3,在模型训练阶段,我们收集了大量页面样本,包括各类管理后台、高危页面等,为模型训练提供丰富与多样化的数据支撑。同时,线上模型将进行定期的更新以保证模型始终保持良好的判别能力,并引入正负反馈机制配合AI模型训练,基于模型识别的情况针对性调优,进一步提升模型准确率。下面简单聊聊各阶段涉及的相关技术。
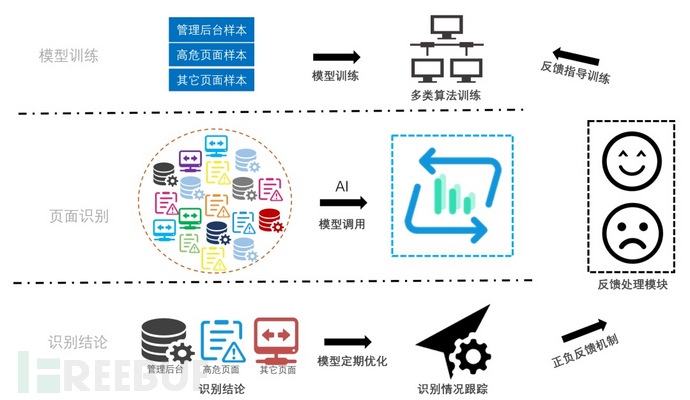 图3 机器学习风险判别模块
图3 机器学习风险判别模块
3.1 数据预处理
前期经过长时间的数据采集、去脏、打标,我们积累了充足的网页源码样本,但是页面的源码需要经过预处理才能转化为模型可理解、可计算的形式。具体过程主要是去除页面中无用的代码、符号等干扰因素,之后将页面进行分词,具体规则简略描述如下:
去除文中所有特殊符号,包含中英文标点符号、emoji表情、特殊字符(如颜文字)等。
去除HTML中标签名,如div、td等;去除HTML中的注释内容等;
英文长句拆分,中文长句拆分等;
计算除标签外文本的信息熵;
等等…….
由于管理后台一般情况下相较普通用户登录页面而言更加简洁,所以这里引入了信息熵来去除相对复杂的页面,比如部分新闻页面中存在登录框导致的误报等,其他步骤则主要是去除干扰的文本,最终获得一系列的英文单词和中文词语。
紧接着,我们选择经典的word2vec对数据做进一步处理。word2vec通过计算向量之间的距离来体现词与词之间的关系,就是简单化的神经 *** ,我们通过训练word2vec模型将文本内容转化为固定长度的数字构成的向量,这些带有文本特征的向量作为机器学习模型输入,优势体现在:
加速模型收敛;
降低输入的维度,节省运算开销;
增加语义信息,有利于后续模型的特征学习。
3.2 算法选择与模型训练
在算法选择阶段,我们结合各算法适用场景与样本特征,进行了多种算法测试,最终选择具备更高准确率与效率的XGBoost作为核心算法。XGBoost是GBDT的工程实现,并行计算、近似建树、对稀疏数据的有效处理以及内存使用优化使得XGBoost更加准确高效。经过word2vec预处理后,页面单词被转换为数字向量输入XGBoost模型,完整处理流程如下:
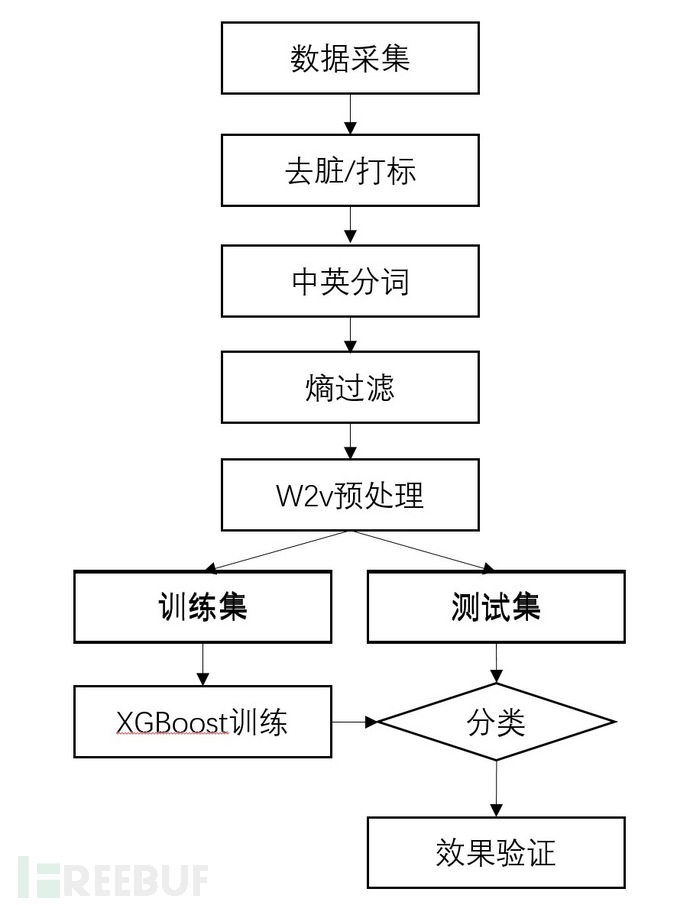 图4 XGBoost算法处理流程
图4 XGBoost算法处理流程
3.2 线上部署与调优
训练成熟的XGBoost模型即具备了页面识别能力,能够从杂乱无章的页面中区分出管理后台。检测出的管理后台将进行人工的二次验证,最终确定识别结果。人工确认的误检部分将输入反馈模块用于后续模型的针对性更新。
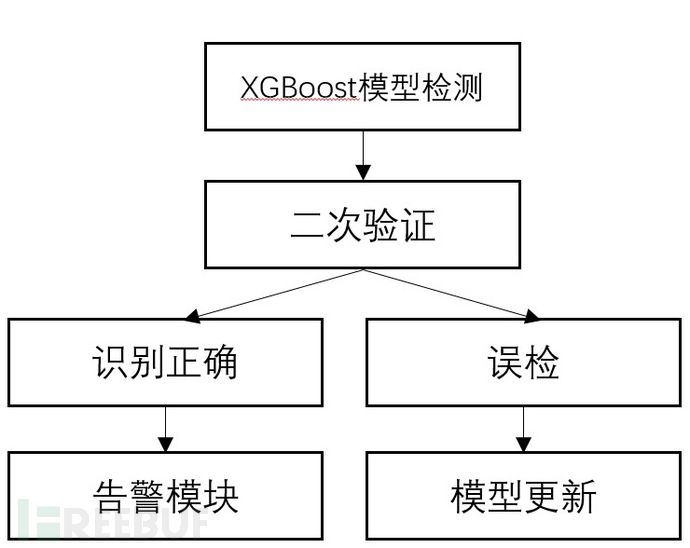 图5 模型调用流程
图5 模型调用流程
四、告警
在上述验证完成之后,识别为Web管理后台的URL会进入告警模块中去,告警模块除了直接告警以外,还肩负着弱口令检测的责任。告警模块会根据URL从疑似登录的流量中检查是否存在该登录接口的弱口令,其识别 *** 和登录行为的识别模式基本一致,在此不再赘述。当发现管理后台存在弱口令之后,一是可以附带弱口令到告警中去,第二也可以针对性做分级运营。
写在最后
基于机器学习分类算法,模型可以自动学习页面特征,效果远远超过传统方案。同时,模型具备良好的泛化性能,除了对管理后台的识别,甚至可以实现对其它特定类型页面的识别,比如框架报错页面等。
此外随着开源组件应用的增多,尤其是部分应用默认未授权可访问,基于以上原因,其实模型也需要具有与时俱进的学习能力,所以我们也集成了反馈处理模块,通过对识别的结果进行反馈实现针对模型的不断优化。当然后续还有很多工作要做,比如跟SOC工单系统打通,可以直接根据业务的处理和反馈情况进行模型调优。
基于机器学习的管理后台识别方案是我们在流量安全分析领域一个小小的尝试,未来我们也将持续探索更复杂的场景与更丰富的解决方案,不断拓展,为流量安全发掘新思路,也希望为业界带来一些新想法。敬请大家关注我们后续的流量系列相关文章。最后我们也希望在探索这些方案的同时能够与大家一起讨论分享,如果你有更好的想法或者对流量安全相关的工作感兴趣,欢迎与我们联系。团队长期招人,简历请投至security@tencent.com
文|宙斯盾流量安全分析团队
晨晨、彦修
相关文章
田园乐王维(田园乐赏析)
田园乐① 王 维 桃红复含宿自动绕线机雨,柳绿更带春烟。 花落家童未扫4万阁下的车,莺啼山客犹眠。注释:①原诗共七maya论坛首,与北宋王安石《题西太一宫》同qq御剑天涯为六言绝句中最优秀的篇章。...
色子骰子的技巧(喝酒摇骰子如何赢翻酒桌)
色子骰子的技巧(喝酒摇骰子如何赢翻酒桌)“大话骰”是一款以骰子为道具非常普遍的酒桌游戏,几乎朋友聚会快速活跃喝酒气氛必备的喝酒游戏。 色...
成昆铁路将恢复开行成RKI-280都至西昌、攀枝花旅客列
中新网成都12月29日电 (记者 王鹏)记者29日晚从中国铁路成都局集团有限公司获悉,从2021年1月1日起,成昆铁路将在白天时段恢复开行成都至西昌、攀枝花方向旅客列车2对。 成昆铁路沿线山...
顿号怎么输入
如今大伙儿在应用电脑上的情况下都是会用电脑键盘开展电脑打字,许多 盆友常常会采用,句点,分号,可是却不清楚顿号怎么打出去,实际上顿号是非常好打的,下边我就来对你说顿号怎么打出去。 前几日我接到...

销售伪劣口罩被抓的人是谁 销售伪劣口罩被抓怎么回事这些口罩都卖哪
近日,安徽省霍山县公安局与县市场监督管理局查获了一起通过淘宝网店销售伪劣医用口罩案。 经查,新型冠状病毒肺炎疫情发生以来,犯罪嫌疑人丁某数次通过多渠道大量低价进购日常防护口罩(非医用外科口罩),利用...

如何让黑客查不到我ip(怎样让黑客查不到我)
本文导读目录: 1、谁教我怎么防止别人查看到自己的IP 2、黑客用什么工具隐藏IP? 3、请问个人电脑如何防止IP被追踪? 4、怎么能防止别人查到自己的IP? 5、怎样上网让别人查不到...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!