基于AI的恶意加密流量检测效果专题研究
经实践验证,基于AI的恶意加密流量检测是一种更有效的 ***
近年来为了确保通信安全和隐私,超过60%的企业 *** 流量已被加密。但殊不知,数据流量的加密在无意之间也为 *** 安全带来了新的隐患,据Gartner预测,2019年后近半数的恶意软件活动将利用某种类型的加密来隐藏交付、命令、控制活动以及数据泄露。
直到现在,处理此问题的传统 *** 是解密流量,并使用诸如新一代防火墙等设备查看流量。这种 *** 耗时较长,破坏了加密技术解决数据隐私的初衷,且需要在 *** 中添加额外的设备。同时不能对无法获取秘钥的加密流量进行解密及检测。
那么问题来了,如何采用一种行之有效的 *** ,甚至能够在加密流量不解密的情况下,来识别它是否是恶意软件或工具产生的恶意加密流量?
随着人工智能技术的发展,通过大量的测试验证,人工智能用于加密流量安全检测将是一种新技术手段。以AI技术赋能恶意流量检测,通过本次实验成功验证了相较传统检测 *** ,通过AI建模、解析和检测在实际效果中获得了显著的提高,其中三种模型在对恶意TLS *** 流分类的结果均达到99%以上,充分展现了基于AI的恶意加密流量检测具有高度的可行性和良好的应用前景。
一、加密流量的复杂性与主流识别技术方案
过去的几年中,合法流量已迅速采用了TLS(安全传输层协议)标准,多达60%的 *** 流量使用了TLS,同时恶意软件也采用了TLS加密来使其通信不被发现,使得威胁检测变得更加困难。在最新的TLSv1.3版本中,ServerHello之后的所有握手消息采取了加密操作,可见明文大大减少,证书信息也变为不可见,使得传统检测 *** 的检测能力大幅削弱。TLSv1.2和TLSv1.3的认证过程对比如下图所示:

图TLSv1.2认证过程
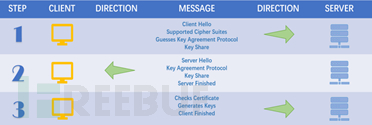
图 TLSv1.3认证过程
虽然TLS加密方式对认证过程的大部分内容进行了加密,但是仍然可以得到一些非加密内容数据来作为训练数据,TLSv1.3的更新让通过证书异常检测的传统检测方式变得不可行,但对AI *** 的影响很小,使用人工智能算法仍然可以发现其中的规律,通过捕获每个会话与会话之间保持静态的Client Hello数据包元素,从中捕获TLS版本、密码套件、压缩选项和扩展列表等字段,以大量的样本信息训练生成AI检测模型,从而进行有效的探索和验证,得出更优检测结果。行之有效的验证了AI对于TLS加密的流量检测更加具有针对性和准确率。
恶意加密流量检测识别技术
1. 加密流量识别技术
对加密流量的检测,业界主流有2种 *** :
- 之一种是将流量进行解密并进行检测,这需要安全检测设备充当通信双方的 *** 或者由客户提供单独的解密证书(只能针对该证书对应的加密流量进行解码);
- 第二种是在不解密的情况下进行安全检测,这通常会采用机器学习的 *** 。
学术界和工业界对机器学习 *** 用于恶意加密流量的检测经历了3次比较大的技术演进:
- 之一次是对数据流的基础TCP会话特征进行统计特征提取,然后构建AI模型进行检测;提取的主要特征是数据包的包长序列、包时间检测序列、包的载荷字节分布等统计特征,利用的是加密通信和正常通信在数据流层面的差异性。
- 第二次是在数据流TCP会话特征的基础上,引入了TLS/SSL应用层协议数据的统计特征。因为,虽然TLS/SSL的数据通信是加密的,但在开始数据通信之前会进行密钥协商和身份认证,这个过程中传输的数据是明文的,提取的统计特征多为客户端和服务端加密算法、证书提取信息等,这2类特征的结合,大幅提高了AI模型检测的准确性,同时可以运用一些加密指纹(例如JA3/JA3S/SSL证书指纹)和证书异常分析技术,有效降低AI模型的检测误报。
- 第三次是引入了TLS/SSL数据流的上下文信息,例如TLS/SSL通信之前会由定位通信目的服务器的DNS上下文,进一步提取DNS上下文的统计特征,能够进一步提高AI模型的准确性。同时,可利用的上下文还包括HTTP上下文。
2. 加密流量检测方案
从大量恶意软件监测分析的情况来看,越来越多的恶意软件采用加密协议进行通信,有研究统计有七十余种恶意软件采用了TLS/SSL加密 *** 进行通信。
除了一些常见的恶意软件家族之外,我们纳入研究和检测的加密通信还包括:
- Shadowsocks翻墙,暗网浏览器通信和加密隧道通信等
- 识别常见和非法VPN软件
另外,也尝试在做加密通信中的恶意行为探测,例如加密通道密码暴力破解、扫描探测和僵尸 *** C2行为等。
二、恶意加密流量数据集
恶意加密流量的收集来源包括:
- 收集恶意样本经沙箱生成的加密流量pcap文件;
- 从相关 *** 上直接下载恶意pcap文件;
- 公司自身研发积累的恶意软件pcap文件。
针对前2个收集来源,简要介绍处理过程:
(一)恶意样本收集
AILab分别从自有威胁情报恶意软件库、 *** 在线杀毒网站库、 *** 恶意软件开源库等种渠道获取恶意样本的Hash值,再将这些Hash值所对应的恶意样本下载后,提交到沙箱进行动态分析,最后抓取它们 *** 行为的pcap包。
(二)恶意软件收集
- APT样本相关的pcap:2.5GB
- 网上 *** 安全数据集:550G,在 *** 中收集恶意软件样本。
- 安全研究或病毒扫描网站:30G
通过安全研究或病毒扫描的网站下载公开的恶意软件样本。
三、数据处理与模型训练
(一)实验总体流程
实验基于公司AI-Matrix建模平台进行。
本实验从收集各类型加密数据开始,经过流量包分析,流量数据处理,流量特征提取,AI模型训练多个步骤,最后得到恶意加密流量的识别模型。
(二)实验数据处理
1.数据预处理
为保证检测引擎的准确性和时效性,数据搜集的准确度、覆盖面是关键。实验数据家族详细分类及数据量,本次实验选取18个家族进行实验。
样本家族 | 数据包大小 | 样本家族 | 数据包大小 |
Virtob | 710M | Tescrypt | 31M |
Yakes | 3.2G | Toga | 611M |
Zbot | 14G | Upatre | 191G |
Zusy | 19G | Virlock | 37G |
Bergat | 100M | Symmi | 5.9G |
Deshacop | 4M | Parite | 3.5G |
Dridex | 1.3G | Razy | 48G |
Dynamer | 2.4G | Sality | 20G |
Kazy | 7G | Skeeyah | 4G |
白样本数据 | 500G+ |
首先将流量包数据通过AI训练平台中的流量引擎解析并提取AI模型预备训练样本,再对提取的预备训练样本进行筛选得到最终的模型训练样本。
得到AI模型训练样本之后,将训练样本根据TLS/SSL会话是否与DNS上下文进行关联分为两类数据集:
- 之一类为关联上DNS上下文的训练数据集;
- 第二类为非关联上DNS上下文的训练数据集;
对以上数据集根据TLS/SSL是否完成身份认证,继续细分为2个子类。
2.特征提取
对于非关联类别的数据主要提取了包长序列的Markov转移矩阵、包时间间隔的Markov转移矩阵、流字节分布、协议握手和证书特征、客户端支持的密码套件列表、客户端支持的TLS扩展、服务器TLS扩展等。
对于关联类别的数据在非关联数据特征提取的方式上增加了对关联流量特征的提取,主要包括全域名长度、域名后缀列表、TTL值等。
3.特征数据分析
为使模型更好的学习到黑样本的特征以及平衡黑白样本数据量,所有实验对数据进行了采样从而得到1:1的训练集分布。为了更加直观的看出数据的可分性,每个实验中对实验数据进行了随机抽样后进行PCA降维,得到二维平面的数据降维图和三维空间的数据降维图。并对各类别数据的黑白样本系数程度进行可视化,以便直观看出特征数据的分布情况。
(1)关联且认证完整类别数据:
样本类型 | 数据量 |
黑样本 | 1157636 |
白样本 | 1157636 |
数据样本降维可视化图:
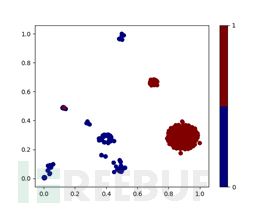

根据两种数据降维图可以观察出该类别样本数据在二维和三维空间上都表现出良好的可分性,算法可以找到一个超平面来对黑白数据进行划分。
黑白样本特征矩阵稀疏程度:


从该类别的黑白样本稀疏程度图可以观察到流的基本特征中稀疏程度很低,其他特征稀疏程度较高,在特征提取和模型参数调优时要注意稀疏特征的影响。
部分特征黑白样本数据分布情况:
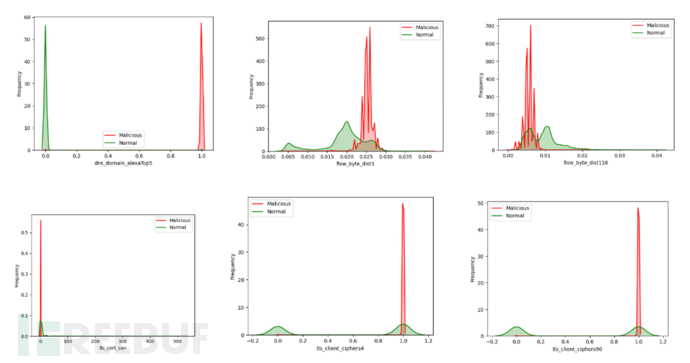
从一些特征的黑白样本数据密度分布图来看,黑白样本在一些特征中有着明显的区分度,可以作为关键特征重点处理。
(2)关联认证不完整类别数据:
样本类型 | 数据量 |
黑样本 | 3414008 |
白样本 | 3414008 |
数据样本降维可视化图:

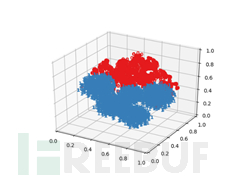
根据两种数据降维图可以观察出该类别样本数据在二维和三维空间上也表现出良好的可分性。
黑白样本特征矩阵稀疏程度:


该类别数据中两种样本的稀疏程度有较为明显的区别,在特征处理时考虑对特征的进一步处理。
部分特征黑白样本数据分布情况:

一部分特征的黑白样本数据密度分布表现出良好的差异程度。
(3)非关联且认证完整类别数据:
样本类型 | 数据量 |
黑样本 | 3735362 |
白样本 | 3735362 |
数据样本降维可视化图:
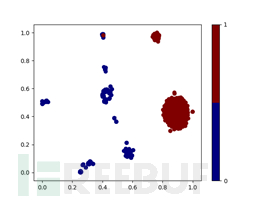

根据两种数据降维图可以观察出该类别样本数据在二维和三维空间上同样表现出良好的可分性。
黑白样本特征矩阵稀疏程度:


该类别的黑白样本稀疏程度与关联且认证完整类别的分布较为相似。
部分特征黑白样本数据分布情况:
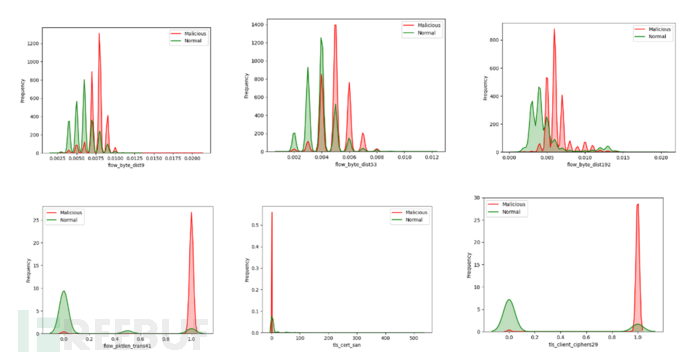
(4)非关联认证不完整类别数据:
样本类型 | 数据量 |
黑样本 | 3015196 |
白样本 | 3015196 |
数据样本降维可视化图:


黑白样本特征矩阵稀疏程度:


该类别的特征稀疏程度与关联认证不完整类别数据稀疏程度相似。
部分特征黑白样本数据分布情况

该类别较其他三种类别在特征数据密度分布上没有特别明显的分布差异,在建模过程中应当尝试更小的学习率或更多的迭代轮数来学习黑白样本的分布差异。
(三)模型训练
1. 模型选取
首先在深度学习与机器学习中,选取了传统机器学习的方式来解决恶意加密流量识别的问题, 选择集成学习中使用率和效果均较高的XGBoost、LightGBM、RandForest算法进行模型训练,且全部采用算法模型的默认参数进行训练。并与经典线性模型LogisticRegression的效果对比。
在数据集的划分中,预留3w数据作为测试集,其余数据按照7:3的比例进行训练集和验证集划分,并在训练过程中采用10折交叉验证进行模型训练和结果评估。
2.模型评价指标
在本次实验中,使用精确率、召回率、准确率以及F1值来综合衡量模型的检测能力。
3. 模型实验效果
四种类别模型分别使用RandomForest,XGBoost,LightGBM,LogisticRegression四种算法在测试集上的表现如下。
(1)关联且认证完整模型的模型评价指标如下表所示:
model | accuracy | recall | precision | f1 |
RandomForest | 0.997166667 | 0.995920005 | 0.998390774 | 0.997153859 |
XGBoost | 0.998166667 | 0.997123938 | 0.99919571 | 0.998158749 |
LightGBM | 0.997466667 | 0.997257709 | 0.99765808 | 0.997457854 |
LogisticRegression | 0.997766667 | 0.996789512 | 0.998726712 | 0.997757172 |
模型测试集上预测结果的混淆矩阵如下图所示:

图 LightGBM,XGBoost,RandomForest,LogisticRegression测试集预测结果混淆矩阵
(2)关联认证不完整模型的模型评价指标如下表所示:
model | accuracy | recall | precision | f1 |
RandomForest | 0.999 | 0.998729182 | 0.999263869 | 0.998996454 |
XGBoost | 0.999433333 | 0.999331148 | 0.99953171 | 0.999431419 |
LightGBM | 0.999466667 | 0.999331148 | 0.999598582 | 0.999464847 |
LogisticRegression | 0.999033333 | 0.998929837 | 0.999130318 | 0.99903006 |
模型测试集上预测结果的混淆矩阵如下图所示:

图 Lightgbm,XGBoost,RandomForest,LogisticRegression测试集预测结果混淆矩阵
(3)不关联且认证完整模型的模型评价指标如下表所示:
model | accuracy | recall | precision | f1 |
RandomForest | 0.9966 | 0.99558558 | 0.997587293 | 0.996585431 |
XGBoost | 0.9958 | 0.994314762 | 0.997249614 | 0.995780025 |
LightGBM | 0.996433333 | 0.994916728 | 0.997920301 | 0.996416251 |
LogisticRegression | 0.9939 | 0.993579024 | 0.994177486 | 0.99387816 |
模型测试集上预测结果的混淆矩阵如下图所示:

图 LightGBM,XGBoost,RandomForest,LogisticRegression测试集预测结果混淆矩阵
(4)不关联认证不完整模型的模型评价指标如下表所示:
model | accuracy | recall | precision | f1 |
RandomForest | 0.9755 | 0.996990168 | 0.955757887 | 0.975938717 |
XGBoost | 0.969733333 | 0.980469534 | 0.959672668 | 0.969959637 |
LightGBM | 0.974333333 | 0.996521972 | 0.954024461 | 0.974810259 |
LogisticRegression | 0.970466666 | 0.996388201 | 0.947104075 | 0.971121251 |
模型测试集上预测结果的混淆矩阵如下图所示:

图 LightGBM,XGBoost,RandomForest,LogisticRegression测试集预测结果混淆矩阵
四个模型中前三个模型在测试集中的验证结果各项指标均大于0.99,第四个模型即关联认证不完整模型测试结果略有下降。实验结果体现了在加密流量不解密检测领域,使用合适的特征提取 *** ,机器学习算法能够取得不错的效果。综合考虑模型的训练成本、参数调优难度和性能评价指标等,我们认为集成学习算法特别是LightGBM在该问题领域的应用效果值得推荐。
四、总结
在恶意加密流量识别中,基于AI算法采用收集和关联TLS、DNS和HTTP元数据,在对恶意TLS *** 流分类的效果上取得了较为准确的结果。可以看出,AI模式下将恶意加密流量分类问题分为四个子模型来解决的 *** ,相较传统单一模型检测 *** 在检出效果上取得了显著的提高。同时展现了基于AI的恶意加密流量检测具有高度的可行性。
相关文章
笑死企鹅肉是什么意思什么梗 笑死企鹅肉梗出处来源是哪里
近期在网络上会常常见到有一些有趣的回应,有一些回应令人啼笑皆非,当女孩在聊很正儿八经的事儿,忽然回应笑死企鹅肉,简直不明就里,那麼,笑死企鹅肉代表什么意思什么鬼?出處来源于是哪里?下边我就而言说。...
想做好创业投资好项目,我们应该做到这几点!
在大家如今的社会发展之中啊,大家愈来愈多的一些年轻朋友们呢都是会挑选去自主创业都是会去在大家如今的那样的一种相对性相对稳定的社会发展之中去掌握好每一个机遇。伴随着互联网技术的迅速发展趋势,全球公共数据...
印尼苏拉威西地震遇难申公元人数升至56人 救援工作仍
中新网1月17日电 据路透社报道,近期,印度尼西亚自然灾害频发。当地时间17日,印尼国家抗灾署(BNPB)称,苏拉威西岛日前发生的6.2级地震已致56人死亡,联合救援队正紧张展开救援工作。 ...
妻子出轨怎么查她和别人微信短信聊天记录获取
近日,克拉拉曝出一组时尚写真大片。照片中,克拉拉或身穿白色复古衬衫,珍珠项链简单点缀颈间;或黑色紧身针织衫,搭配夸张廓形牛仔长裙,显得整个人高级有质感。蓝色格纹长款西...
毕业作文(关于毕业了作文)
毕业作文(关于毕业了作文) 初中生优秀作文:我们毕业了 我们行走在时间的河畔,在随着时间行进的方向前进的同时,也在不断地在时间中洒下自己的记忆。现在,我们已经走了那么久,忽然发现,我们已经将最...
怎样监听妻子的手机通话记录
已删除的手机微信记录如何恢复?手机微信现在是大家应用数最多的一款手机软件之一,能够谈职业生涯能够沟通交流事儿,那麼大家一不小心把手机微信记录手误删了会话款,该怎么快速修复?出来我具体指导每个人几个方面...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!