更适合文本分类的轻量级预训练模型
自 BERT 起,预训练语言模型沿着海量训练数据和庞大 *** 结构的方向在不断发展着。在12月落幕的 NeurIPS 2020 会议上,语言模型 GPT-3 荣膺更佳论文奖。OpenAI 的研究人员使用了多达 45TB 的文本数据来训练它的 1750 亿个参数。GPT-3 不仅仅是“变得更大”,它用“Few-Shot”学习替代了 FineTune,能够出色完成代码生成、领域问答、吉他谱曲等高难度的复合型 NLP 任务。
那么,在相反的道路上,当数据受限并且算力不足,是否有轻量级的预训练模型能够帮助我们更好地处理文本分类等经典NLP问题呢?
AllenAI 团队开源的 VAMPIRE(Variational Methods for Pretraining In Resource-limited Environments)正是这样一款模型。全文《Variational Pretraining for Semi-supervised Text Classi?cation》收录于ACL-2019。
本文将详细介绍一种基于预训练半监督的文本分类轻量型模型,即 VAMPIRE 模型,为解决由于大量数据和高昂计算力导致的资源不足问题提供一些思路。
01变分自编码器
VAMPIRE 从 VAE 中借鉴了不少思路,在详细介绍它之前,先来说说什么是 Variational AutoEncoder(VAE),中文译作变分自编码器。VAE 出自 ICLR-2014 的 《Auto-Encoding Variational Bayes》,是一种图像生成技术,近年来也被迁移到 NLP 中作为一种文本生成模型。原文中有大段大段的公式推导,全部理解需要费不少功夫。不过对于 VAMPIRE 来说,重要的是弄明白 VAE 是建立在什么样的假设之上,它是通过什么样的方式来实现文本生成的。
和 encoder-decoder 架构一样,VAE 也是通过“编码”和“解码”来完成对输入句子的重建。两者的区别在于,发源于 CV 的 VAE 并不是一种天然有序的 NLP 模型。在理解 VAE 之前,需要先彻底抛下头脑中关于 Seq2Seq 那种 one by one 生成方式的固有印象。输入序列中的每个词可以是相关的,也可以互相独立的,这取决于你使用什么样的编码器。但是,输出序列中的每个词,一定是互不依赖的。它们被各自建模,同时生成。为了便于理解,我们暂且将重建任务看成是对单个词的建模。这一过程可以用更广义的分布-采样概念来描述:
○ 对于一个离散样本X,计算其概率分布,根据分布表达式进行采样,生成新的离散样本 X'。令 X' 无限逼近 X。
如果用 encoder-decoder 的术语来说,“计算概率分布”即“编码”,“分布表达式”即隐 层,“采样生成”即“解码”。这里有一个难点。X 是个离散变量,它很有可能服从某个奇奇怪怪的 分布,根本就写不出具体的表达式,更别提根据表达式来采样了。因此,VAE 以正态分布作为搭桥, 先将 X 变换到正态分布 N(X) 上,再根据公式进行采样得到 Z,对 Z 进行变换生成 X'。至于 X -> N(X) 和 Z -> X',就直接扔进神经 *** 学出来。一个特定的正态分布,只由均值和方差决定。因此, X -> N(X) 的变换,实际使用了两个神经 *** ,分别估算均值 u 和方差 sigma。
以上是对于单个词的建模。当输入的是 n 个词组成的句子时,在每个词位置都需要进行上述处理。也就是说,有 n 组正态分布,对应着 n 组均值和 n 组方差。好了,现在可以画出整个前向计算的流程图了:
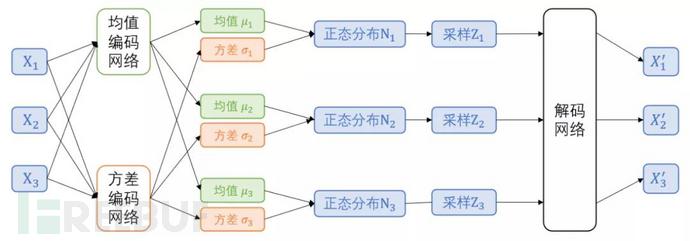
在前向计算过程中,每个 X 都是 embedding 向量,经编码产生的均值和方差也同样是向量(假设维 度为dim)。那么,实际上生成了 dim 个正态分布,它们各自独立采样,组成维度为 dim 向量 Z。从 Pytorch 示例代码中可以更直观地看到数据流向:

VAE 的优化目标分为两部分。之一部分是重建目标,即 X'=X:

在不加入额外约束项时,模型可以很轻松地做到 100% 地还原 X,只要让方差全部为 0,均值取原值即可。显然,这样的模型是不具备真正生成能力的。因此,VAE 的优化目标还包含第二部分,使用 KL 散度把 Z(X) 拉向标准正太分布N(0, I)。可以理解为正则化项,或是对生成 *** 加噪。

两个 loss 互相对抗,同步学习优化。
02 VAMPIRE
现在可以正式介绍 VAMPIRE 了。这是一个为算力和数据双双受限的情况设计的轻量预训练模型,它的典型应用场景是半监督文本分类。VAMPIRE 在本质上是一个文档话题模型,它从一开始就抛弃了序列信息,将句子当作 BOW(Bag of Words)进行建模。模型捕捉的是词与词的共现信息,重建的是词频向量。这样的设计使得无论是模型训练还是预测推理都大大加快。
对于输入句子 X,VAMPIRE 统计词表中每个词的频次,构建词频向量作为句子表示。编码器部分是和 VAE 一样的均值方差预测,然后进行重参数采样:
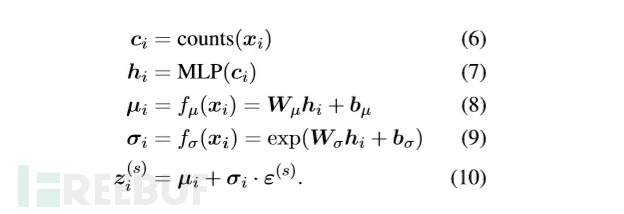
解码器部分做了适配改造,先对采样变量 Z 做一次 softmax 得到 theta,作者将其解释为对隐话题的分布计算。其中,公式13 即重建目标 loss1。
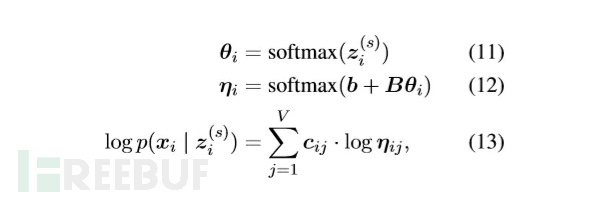
在完成预训练后,theta 被记为 vampire embedding,参与下游任务。和 Bert 等模型不同的是, vampire embedding 作为辅助话题信息,并不能单独完成编码训练。它需要和 word embedding 融合在一起,共同进行分类预测:

03 应用场景
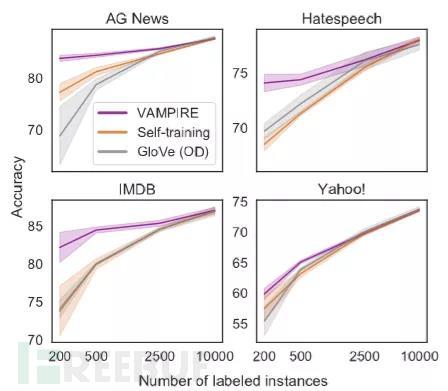
在低资源场景下,当算力受限并且也没有可观的领域数据时,VAMPIRE 等轻量级的预训练模型也可以作为一种备选方案。作者在 AG News、Hatespeech、IMDB 和 Yahoo! 四个任务上,测试了 VAMPIRE 与基线词向量模型在标注数据量从 200~10000 范围内的分类准确度。从图上可以明显地观察到,在标注数据不足 2000 条时,VAMPIRE 模型的表现较基线有大幅度的提升。
04总结
ELMO、BERT 和 GPT 等预训练模型的出现,彻底革新了半监督 NLP 的研究。在海量无标注数据上训练的文本向量表示,不仅能够显著提升下游任务的性能,而且这种助力不局限于单一的任务类型。
相关文章
it黑客网,如何当下载黑客软件,黑客张长贵
postMessage会把你放入的任何目标序列化,然后发送到另一个web worker,反序列化并放入内存中,这是一个适当缓慢的进程。 [1][2]黑客接单 测验环境: Server2012R2 x6...
黑客攻击代码大全,黑彩平台被黑找黑客,合肥在哪找黑客
上篇我讲了怎么在上传文件中侵略服务器,這次咱们略微多讲一点。 URL : http://50.116.13.242/index.php The password for the next level...
深圳真实在飞空姐预约联系方式绿色入口曹英
深圳真实在飞空姐预约联系方式绿色入口【曹英】,上海是一座成功人士的聚集地,对商业模特的需求也是比较大的,今天明星商务分享模特访梦,年龄江北区 女 32,婚姻:未婚,学历:高中,气质:深圳真实在飞空姐预...
韩国统一部:坚王洪文近况定履行韩朝协议
新华社首尔1月9日电(记者陆睿 耿学鹏)韩国统一部9日就朝鲜劳动党第八次代表大会发布的内容表示,韩国政府履行韩朝协议的意志是坚定的,韩方一贯主张实现朝鲜半岛无核化和持久和平、发展韩朝关系。 ...
找黑客盗取qq靠谱吗(黑客盗取qq号)
楼主应该去举报他聊天窗口有得举报只要他去过你空间你可以用找我就Q我来聊天,然后举报 一般有的黑客不可靠,甚至你花钱请的人也许是骇客,不过你可以试试能否申诉。实在不行我认识一个黑客,+QQ3174818...
怎么样查看身边人开房信息
. 孩子频繁眨眼有时候并不是孩子的错,有可能是眼睛出了问题,孩子频繁眨眼有炎症作用或抽动症等多方面原因,那么孩子频繁眨眼怎么办?接下来友谊长存小编就来说说。 孩子频繁眨眼是怎么回事 平时经常会有...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!